
在进入 AI 领域之前,我一直从事模型和算法开发,持有一种非常传统的计算机科学(CS)视角。随着大模型的普及,我们观察到 AI 在编程领域(如 Cursor, Claude code)的表现进步最快,因为在这个闭环内,我们自己开发、自己使用、自己测试并优化数据。当时我们很自然地产生了一个想法:既然 AI 在代码领域表现如此惊人,那么在大数据分析领域,AI 难道不是"降维打击"吗?
但在实际落地过程中,我们发现这种想法过于理想化了。

过去一年,行业内涌现了大量 Text-to-SQL 或 Chat-to-Data 的产品。技术逻辑看似完美:用户提问 -> AI转译 -> 数据库执行 -> 返回结果。但在实际落地中,AskTable 团队识别出了两个核心痛点,这促使了技术路线的根本性调整。
理想状态下,AI是连接业务人员与数据库的桥梁。但现实中,落地一个AI数据项目需要协调业务方(提需求)、数据团队(理口径)、Ops团队(开权限)以及老板(看结果)。技术支持团队往往被淹没在跨部门的沟通噪音中。AI并没有自动消除组织架构的壁垒,反而因为对数据准确性的高要求,增加了由于上下文缺失带来的沟通成本。
这是更深层次的技术哲学问题。
结论: 对话(Chat)并不是人类思考数据的方式。强行用线性对话去承载发散性的分析思维,是对用户认知负荷的加重,而非减负。
通过观察用户的反馈,我们意识到:对话,并不是人类思考数据的方式。
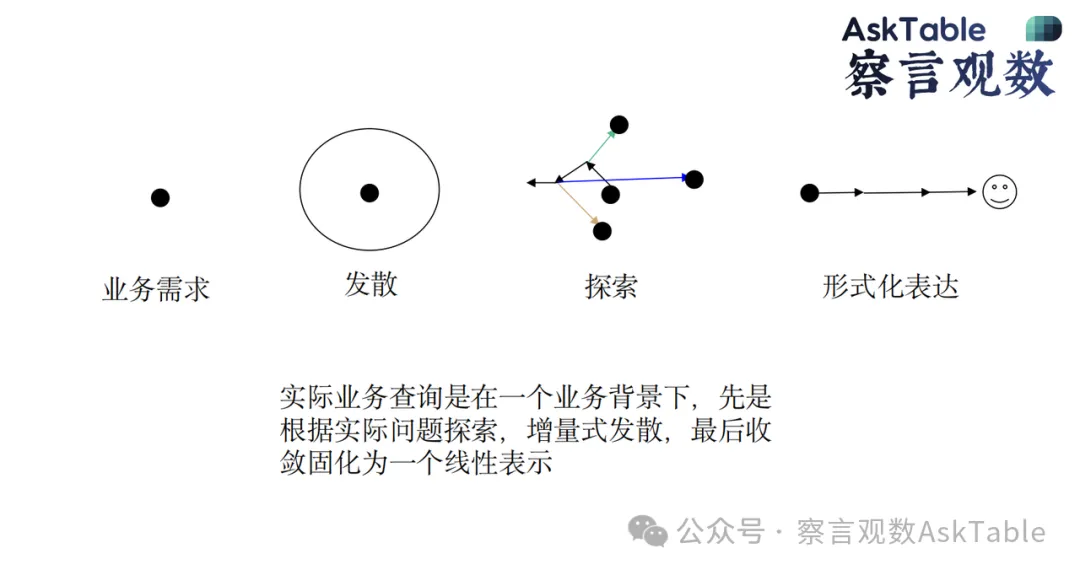
业务查询通常遵循"接收需求 -> 发散 -> 探索 -> 收敛"的过程。而对话是线性的——提出问题 A,得到结果 B。如果你想回过头做横向探索,对话框会变得非常笨重。对话无法包容分析师那种发散式的探索方法。
我们认为,数据分析本质上是一个建模过程。人类对世界、对业务在内心都有一个"心理表征",这种表征很难被言语化。分析的过程,就是通过随手记录、拖拽、SQL 或代码等手段,将这种复杂的心理表征逐步"降维",最终收束到具体场景中,给出一个图表、一个结论或一个决策参考。
用户说出来的那句话,往往是脑中无数想法筛选后的"简化表达",它并不是对数据最真实的思考。
如何界定AI在系统中的职责至关重要。AskTable 提出了一套清晰的工程原则:AI应用就是工程化所有"可验证"的事情。
AskTable 的策略是:绝不让AI去"猜"不可验证的东西(如凭空生成一个精美大屏),而是利用AI极低的边际成本,去解决所有可验证的代码生成和数据处理任务。
在企业级数据场景下,准确性是生命线。AskTable 强调:

为了实现"所想即所得",我们在产品中进行了两次核心探索:
在做新产品探索之前,我们做了一个实验,尝试将 Agent 置于一个集成了 Python、SQL、DuckDB、VectorSearch、JavaScript等工具的融合环境中。给它一个目标,让它自己去试错、反馈、迭代,并生成包含思考过程(Plan)的深度报告。虽然目前这还未完全达到生产可用的地步,但它验证了 AI 在给定工具和初始条件下,能够给出意料之外的优质结果。
这是我们最近内测的核心功能,旨在打破线性的束缚。
不同于传统BI的拖拽或ChatBI的问答,AskTable 的画布将分析过程抽象为可编排的节点。整个产品由"节点"组成,通过点与边表示数据的流向,而不是简单的问答历史。

在画布中,用户可以通过连线或选中多个节点,显式地定义AI的Context(上下文)。
这种架构让分析过程变成了一个可视化的思维导图。用户不再受限于编程语言或单一的对话窗口,而是通过节点的组合,完成从"心理表征"到"形式化表达"的映射。
在技术实现上,AskTable 始终遵循以下原则:
写一个 Agent 并不难,但在 2025 年这个时间节点,如何挖掘人与 AI 交互的新可能性才是真正的挑战。我们不希望把人和 AI 割裂开来,而是希望将琐碎的可验证工作封装在 AI 内部,让人能够自由地进行思维探索。
AI 负责繁琐、可验证的逻辑,
人类专注在抽象思考与业务探索。
我们正在寻找对业务和数据敏感的伙伴参与我们的画布功能内测。如果你有任何想法,或者想借鉴我们的思路,欢迎与我们交流。

AskTable 团队致力于探索人机协作的下一个边界。



