
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家
一个优秀的数据分析师和一个通用 AI 的差距在哪里?
不是知识量,不是算力,更不是谁"更懂数据"。
差距在于方法论。
一个资深数据分析师看到销售额下降 20%,不会泛泛地回答"可能有多种原因"。他会本能地:
这套流程,是他多年实践沉淀下来的"隐性知识"——他知道先看什么、后看什么、哪些指标是关键、哪些噪声可以忽略。
通用 AI 缺的不是数据分析的知识,而是可执行的方法论框架。它知道很多分析技术,但不知道"在这个业务场景下,应该用什么顺序、什么标准、什么粒度去做分析"。
AskTable 做的事情,就是把这些隐性知识提取出来,打包成 AI 可以理解和执行的能力。
这篇文章不讲"有什么"(如果你想知道 AskTable 内置了哪些技能和智能体,请看这篇文章),而是讲**"怎么做到的"**——从专家经验到系统化能力,从定制到标准化,AskTable 是如何一步步完成这个"能力封装"过程的。
每个资深数据分析师都有一套自己的分析框架,但他们往往说不清楚。如果你问他"你是怎么分析销售下降的",他可能回答"就是看看数据嘛"。
但实际上,他的分析过程是高度结构化的:
发现异常 → 确认基线 → 多维度拆解 → 定位核心驱动因子 → 排除偶发因素 → 给出建议
这套流程包含三个层面的知识:
这些就是数据分析师的"隐性知识"——它们存在于经验中,但从未被系统地编码。
为什么这些知识难以传承?因为它们有三个典型特征:
特征一:直觉化
资深分析师能"一眼看出问题",但这不是魔法,而是大量实践形成的模式识别能力。他的大脑里存储了成百上千个"数据模式 - 业务原因"的映射关系,看到数据就能自动匹配。
特征二:情境化
同一个分析动作,在不同行业、不同公司、不同时期的执行方式完全不同。比如"销售额下降"的分析:
通用 AI 缺乏这种情境化的判断力。
特征三:非标准化
不同分析师的分析报告风格差异巨大:有人喜欢先给数据,有人喜欢先给结论;有人注重细节,有人注重大局。但优秀的分析师都有一个共同点——他们的报告能让非数据人员快速理解并采取行动。
AskTable 的做法是:把隐性知识变成显式指令,把显式指令变成可复用的技能。
具体来说,AskTable 将每个技能拆解为四个要素:
| 要素 | 说明 | 示例 |
|---|---|---|
| 触发条件 | 什么时候应该使用这个技能 | 用户问"为什么下降"或检测到指标偏离基线 |
| 执行流程 | 分步骤的分析指令 | 先计算基线,再做维度拆解,然后归因 |
| 判断标准 | 阈值、统计方法、业务规则 | 偏离超过 2 个标准差视为异常 |
| 输出规范 | 结果的结构和表达方式 | 结论先行、数据支撑、建议可执行 |
每个技能本质上是一段结构化的系统指令,它告诉 AI Agent:
"当用户提出这类问题时,按照这个流程、用这些标准、以这种格式来回答。"
传统的软件系统中,分析能力是通过代码实现的。比如异常检测,你可能需要写几百行 Python 代码来处理数据清洗、统计计算、可视化展示。
但在 AI Agent 时代,能力封装的方式发生了根本变化:
代码实现:数据清洗 → 统计计算 → 可视化 → 结果输出(工程师维护)
指令实现:告诉 AI "如何分析"→ AI 自主执行(行业专家维护)
指令化封装的核心优势:
AskTable 的技能开发过程遵循一个独特的循环:
行业专家经验 → 结构化分析框架 → AI 可执行指令 → 实际效果验证 → 指令迭代优化 → 固化为标准化技能
这个过程的关键在于:技能不是代码,而是 AI 可理解的指令。这意味着:
这也是 AskTable Skill 系统的核心设计理念——用指令而非代码来定义能力。关于 Skill 系统的技术架构细节,可以参考这篇深入解析。
每个内置技能都经历了完整的迭代周期:
V1:初始版本 - 基于行业通用方法论编写基础指令
↓
V2:真实数据测试 - 用客户数据验证指令的有效性
↓
V3:对比资深分析师 - 找差距,调整判断标准和流程
↓
V4:多场景适配 - 确保在不同行业、不同数据规模下都有效
↓
V5:标准化发布 - 固化为准化技能,纳入内置技能库
以"异常检测"技能为例,最初的版本只是简单地比较当前值与历史平均值的偏差。经过多轮迭代后,现在的版本能够:
AskTable 内置了 11 种技能,它们覆盖了一个专业数据分析师日常工作中的核心能力。
下面从"能力封装"的视角,逐一解读每种技能是如何把分析方法论变成 AI 可执行指令的。
分析师怎么做:老分析师看一眼趋势图就知道"这个点不对"。他的判断来自对历史波动的直觉理解。
AskTable 怎么封装:
核心方法论:异常不是绝对值的问题,而是"偏离正常模式"的问题。
典型场景:
分析师怎么做:结合历史趋势、季节性、已知业务事件,给出一个"大概"的预判。
AskTable 怎么封装:
核心方法论:预测不只是给出一个数字,更要给出信心程度和风险边界。
典型场景:
分析师怎么做:从总销售额 → 分区域 → 分品类 → 分时间段,一层层找到问题根源。
AskTable 怎么封装:
核心方法论:下钻不是无目的探索,而是"找到贡献最大的差异来源"。
典型场景:
分析师怎么做:自然地想到环比、同比、跟竞品比、跟目标比。
AskTable 怎么封装:
核心方法论:对比不是罗列数据,而是"找到有意义的参照系"。
典型场景:
分析师怎么做:收入增长了,是价格上涨还是销量增加?利润提高了,是成本下降还是效率提升?
AskTable 怎么封装:
核心方法论:归因不只是列出原因,而是"量化每个因素的贡献度"。
典型场景:
分析师怎么做:老板问"如果营收下降 30% 怎么办",分析师会在脑子里快速推演。
AskTable 怎么封装:
核心方法论:压力测试不是吓唬人,而是"提前识别风险边界"。
典型场景:
分析师怎么做:"每到周末销量就下滑"、"我们旺季在 Q3"——这些是经验之谈。
AskTable 怎么封装:
核心方法论:周期分析的价值在于"区分真趋势和假波动"。
典型场景:
分析师怎么做:先放核心结论,再放关键数据,然后是详细分析和建议——每份报告都有固定套路。
AskTable 怎么封装:
核心方法论:报告不是数据堆砌,而是"有逻辑的叙事结构"。
典型场景:
分析师怎么做:把"转化率下降 3.2 个百分点"翻译成"每 100 个访客少成交了 3 个人"。
AskTable 怎么封装:
核心方法论:好的指标解读让"非数据人员也能听懂数据在说什么"。
典型场景:
分析师怎么做:拿到数据先看有没有缺失、有没有重复、有没有明显不合逻辑的值。
AskTable 怎么封装:
核心方法论:数据质量检查是分析的前提,不是可选项。
典型场景:
分析师怎么做:把"p 值 < 0.05"翻译成"这个差异在统计上是显著的,不是随机波动"。
AskTable 怎么封装:
核心方法论:数据分析的价值不在于分析本身,而在于"让决策者理解并采取行动"。
典型场景:
这 11 种技能不是孤立的,它们之间存在清晰的逻辑关系:
数据质量检测(前提)→ 异常检测(发现问题)→ 下钻/对比/归因/周期(诊断问题)
↓
指标解读/业务语言生成(翻译结果)← 预测趋势/压力测试(预判未来)
↓
编排报告(输出成果)
这个关系图谱揭示了一个完整的分析工作流:从确保数据可靠开始,到发现问题、诊断问题、预判未来,最终输出可理解的成果。每个技能都是工作流中的一个环节,可以独立使用,也可以组合使用。
11 种技能是工具箱,但工具本身不会自己工作。智能体的本质,就是给这些工具配上角色、业务知识和工作习惯。
用一句话区分:
智能体 = 技能组合 + 角色设定 + 业务知识 + 工作习惯
举个例子:
异常检测技能 = "能识别数据异常"
↓
门店经营分析师 = "你是一家连锁零售品牌的经营顾问,关注销售、客流、库存,
发现异常后主动推送日报,优先关注 Top 20 门店"
同样的异常检测技能,放在不同智能体里,关注点、告警方式、报告格式都不一样。
你可能会有疑问:既然技能是能力单元,为什么不直接让用户自己组合技能?
原因有三:
第一,技能组合不是简单的叠加。
一个门店经营分析师需要的不只是"异常检测 + 对比分析 + 编排报告"三个技能的叠加。它还需要:
这些"知道",来自对门店经营业务的深度理解,是单个技能无法提供的。
第二,用户需要的是"人",不是"工具"。
业务人员更习惯与"人"打交道,而不是与"工具"打交道。你不需要告诉一个门店经营分析师"先用异常检测,再用对比分析",你只需要说"看看今天的经营情况怎么样",他就会自动选择合适的方法和流程。
智能体提供了这种"自然交互"的能力——你只需要说明意图,它来完成剩下的事情。
第三,智能体有自己的"工作习惯"。
智能体不只是被动响应用户请求,它还有主动工作的能力:
这些"工作习惯"是智能体区别于技能组合的重要特征。
AskTable 内置的 9 个智能体,每个都是经过验证的"角色配方":
| 智能体 | 技能组合 | 角色设定关键词 |
|---|---|---|
| 门店经营分析师 | 异常检测 + 对比分析 + 编排报告 | "经验丰富的门店经营顾问" |
| 电商数据盯盘助手 | 异常检测 + 周期分析 + 指标解读 | "勤勉的电商运营搭档" |
| 财务数据分析师 | 归因分析 + 压力测试 + 数据质量检测 | "专业的财务分析师" |
| 市场洞察分析师 | 对比分析 + 趋势预测 + 编排报告 | "敏锐的市场情报专家" |
| 供应链监控官 | 异常检测 + 周期分析 + 指标解读 | "细致的供应链管家" |
| 用户增长分析师 | 下钻指标 + 归因分析 + 趋势预测 | "专注增长的数据专家" |
| 高管数据助手 | 指标解读 + 编排报告 + 异常检测 | "简洁高效的高管助理" |
| 经营红黄灯分析师 | 异常检测 + 对比分析 + 指标解读 | "敏锐的经营健康顾问" |
| 数据质量守护者 | 数据质量检测 + 业务语言生成 | "严谨的数据质量卫士" |
每个智能体都经过精心设计,确保:
AskTable 对智能体的定义不是"预设配置",而是**"可以一起工作的虚拟同事"**。
这意味着:
与传统 BI 工具不同,AskTable 的智能体具有主动工作的能力。这种"主动性"是智能体的核心特征之一:
传统 BI 工具:用户主动查询 → 工具被动响应
AskTable 智能体:智能体主动监测 → 发现异常 → 主动推送告警
这种主动性的实现,依赖于智能体的两个能力:
关于 AskTable 的 Agent 架构设计,可以参考这篇架构解析。关于记忆系统如何让智能体"记住"你的偏好,可以阅读永久记忆系统。
AskTable 的能力封装建立在 Skill 系统之上。这个系统的关键设计决策是:技能是数据,不是代码。
class SkillModel(Base):
id: UUID # 技能唯一标识
project_id: str # 所属项目
name: str # 技能名称
description: str # 技能描述(供 Agent 理解)
content: str # 技能指令内容
created_at: datetime
modified_at: datetime
这个简洁的数据模型背后,是一套完整的能力封装体系:
content 字段存储的是纯文本指令,不是代码逻辑project_id 实现了项目级隔离,不同项目可以有不同技能库早期的设计考虑过用 YAML 或 JSON 文件来管理技能指令,但最终选择了数据库存储。原因如下:
modified_at 字段记录每次变更时间,方便审计project_id 天然实现项目级隔离Skill 通过 skill_ids 与 Data Agent 和 Conversation 关联:
# Data Agent 关联
class DataAgentModel:
skill_ids: list[str] # 该 Agent 可用的技能列表
# Conversation 关联
class ConversationModel:
skill_ids: list[str] # 该会话可用的技能列表
这种设计实现了技能的灵活组合:同一个技能可以被多个智能体使用,同一个智能体可以拥有多个技能。
技能不是全部塞给 Agent 的。AskTable 采用三层加载机制,确保每次对话只加载必要的技能:
| 优先级 | 来源 | 说明 |
|---|---|---|
| 1 | explicit | 用户显式指定的技能 |
| 2 | agent | 当前智能体关联的技能 |
| 3 | project | 项目级别的默认技能 |
graph TD
A[用户发起分析请求] --> B{显式指定了技能?}
B -->|是| C[加载显式技能 - 最高优先级]
B -->|否| D{有 Data Agent?}
D -->|是| E[加载 Agent 关联技能]
D -->|否| F{项目有默认技能?}
F -->|是| G[加载项目默认技能]
F -->|否| H[使用基础能力]
C --> I[activate_skill 工具]
E --> I
G --> I
这个设计的核心价值:
技能系统支持热插拔——在系统运行过程中随时添加、删除、修改技能,不需要重启服务或重新部署。
这对于能力封装至关重要:
async def activate_skill(skill_name: str) -> str:
"""激活指定技能,返回完整的技能指令。"""
if skill_name not in skill_map:
return f"技能 '{skill_name}' 不存在"
return skill_map[skill_name] # 返回完整指令
这个看似简单的工具,是能力封装的核心枢纽:
整个过程是动态的、按需的、可追踪的。
用户问:"今天销售额怎么下降了这么多?"
Step 1: Agent 收到用户请求
→ 理解用户意图:分析销售下降原因
Step 2: Agent 推理需要什么技能
→ 判断需要:异常检测 + 下钻指标 + 归因分析
Step 3: 调用 activate_skill("异常检测")
→ 获得异常检测技能指令
→ 执行:计算基线,确认偏离程度
Step 4: 调用 activate_skill("下钻指标")
→ 获得下钻指标技能指令
→ 执行:按区域、品类、时段拆解
Step 5: 调用 activate_skill("归因分析")
→ 获得归因分析技能指令
→ 执行:量化各因子贡献度
Step 6: 综合所有分析结果,生成回复
→ 结论先行:今天销售额下降 20%,主要受华东区 X 品类影响
→ 数据支撑:具体数据和分析
→ 改进建议:建议关注...
AskTable 提供了 Skill Editor,让非技术人员也能参与技能的设计和优化:
这意味着:能力封装不再是工程师的专利,行业专家可以直接参与。
打开 Skill Editor → 选择或新建技能 → 编辑指令内容 → 点击"测试"
→ 查看 AI 输出效果 → 调整指令 → 再次测试 → 满意后保存发布
这个工作流的最大特点是低门槛——不需要编程知识,不需要理解代码逻辑,只需要懂得业务分析方法论,就能创建和优化技能。
AskTable 内置的 11 种技能和 9 个智能体覆盖了通用场景,但每个行业、每个企业都有自己的独特方法论。
AskTable 的真正价值,不在于提供了什么,而在于你能往里加什么。
以下场景,建议你创建自定义 Skill:
创建一个自定义 Skill,本质上是把你的分析方法论"翻译"成 AI 可执行的指令:
第一步:梳理你的分析框架
拿一个具体的分析场景,写下资深分析师的完整思考过程:
场景:分析月度销售下降
1. 先确认基线:和过去 3 个月平均值比,偏离多少?
2. 排除数据问题:数据有没有缺失?统计口径有没有变化?
3. 多维度拆解:按区域、品类、渠道分别看
4. 找核心驱动:哪个维度贡献了最大差异?
5. 排除偶发因素:天气、节假日、系统故障
6. 给出建议:下一步该关注什么、做什么
第二步:结构化你的判断标准
- 异常阈值:偏离基线超过 15% 视为异常
- 关键维度:华东区 > 华南区 > 华北区(按营收权重)
- 报告格式:结论先行,3 个关键发现,2 个建议
第三步:编写技能指令
在 Skill Editor 中,将上述框架写成 AI 可理解的指令:
你是一个零售销售分析专家。当分析销售数据时,按以下流程执行:
1. 【确认基线】计算近3个月移动平均,判断当前值偏离程度
2. 【数据校验】检查数据完整性和一致性
3. 【维度拆解】按区域(华东>华南>华北)、品类、渠道拆解
4. 【归因定位】找出贡献差异最大的维度,下钻到可操作粒度
5. 【排除偶发】检查天气/节假日/系统等外部因素
6. 【输出建议】给出最多3条具体可执行的改进建议
判断标准:
- 偏离基线 >15% 标记为显著异常
- 优先关注华东区域(营收占比 40%)
输出格式:
- 先给结论(1句话)
- 再列3个关键发现
- 最后给2个改进建议
第四步:测试和迭代
根据客户的反馈,我们总结了几个编写高质量技能指令的建议:
建议一:用"你"来定义角色
✅ 好:"你是一位有10年经验的零售行业分析师..."
❌ 差:"这个技能用于分析销售数据..."
用"你"来开头,能让 AI 更好地理解自己的身份和工作范围。
建议二:用编号定义流程
✅ 好:
1. 第一步做什么
2. 第二步做什么
3. 第三步做什么
❌ 差:
"先做这个,然后那个,再看看..."
编号清晰的流程让 AI 更容易按顺序执行,避免遗漏步骤。
建议三:用具体数字定义标准
✅ 好:"偏离基线超过 15% 视为显著异常"
❌ 差:"偏离比较大时要特别注意"
AI 需要明确的数字边界,而不是模糊的描述。
建议四:定义输出格式
✅ 好:
输出格式:
- 结论(1句话)
- 3个关键发现
- 2个改进建议
❌ 差:
"给出分析结果"
明确的输出格式确保每次分析的一致性。
当你的自定义 Skill 成熟后,可以进一步组合成行业智能体:
自定义技能 × N + 角色设定 + 业务知识 = 你的专属行业智能体
比如,一个连锁餐饮品牌可以创建:
然后将这些技能组合成"餐饮经营分析师"智能体。
内置智能体(通用)→ 自定义 Skill(行业专属)→ 自定义智能体(企业专属)
这个扩展路径让企业可以从"开箱即用"开始,逐步构建自己的专属 AI 分析团队:
背景:200 家门店的连锁零售品牌,区域经理每天要花 2 小时手工汇总各门店数据、写经营日报。
痛点:
方案:
效果:
"以前我每天花两小时做报表,现在 5 分钟就出来了。多出来的时间,我终于可以去门店看看实际的经营情况了。" —— 华东区运营总监
关键成功因素:
背景:中型电商公司,运营团队每天要盯销售大盘、流量、转化、客单价等多个核心指标。
痛点:
方案:
效果:
"最明显的变化是,我们不再被数据追着跑,而是可以主动做策略调整。而且新来的运营同事,有了这些自定义的 Skill 指导,上手快了很多。" —— 电商运营负责人
关键成功因素:
AskTable 的本质,不是创造了一个"更聪明的 AI",而是搭建了一座桥梁——把数据分析师的隐性经验,翻译成 AI 可以执行的结构化指令。
这道"翻译题"的关键步骤是:
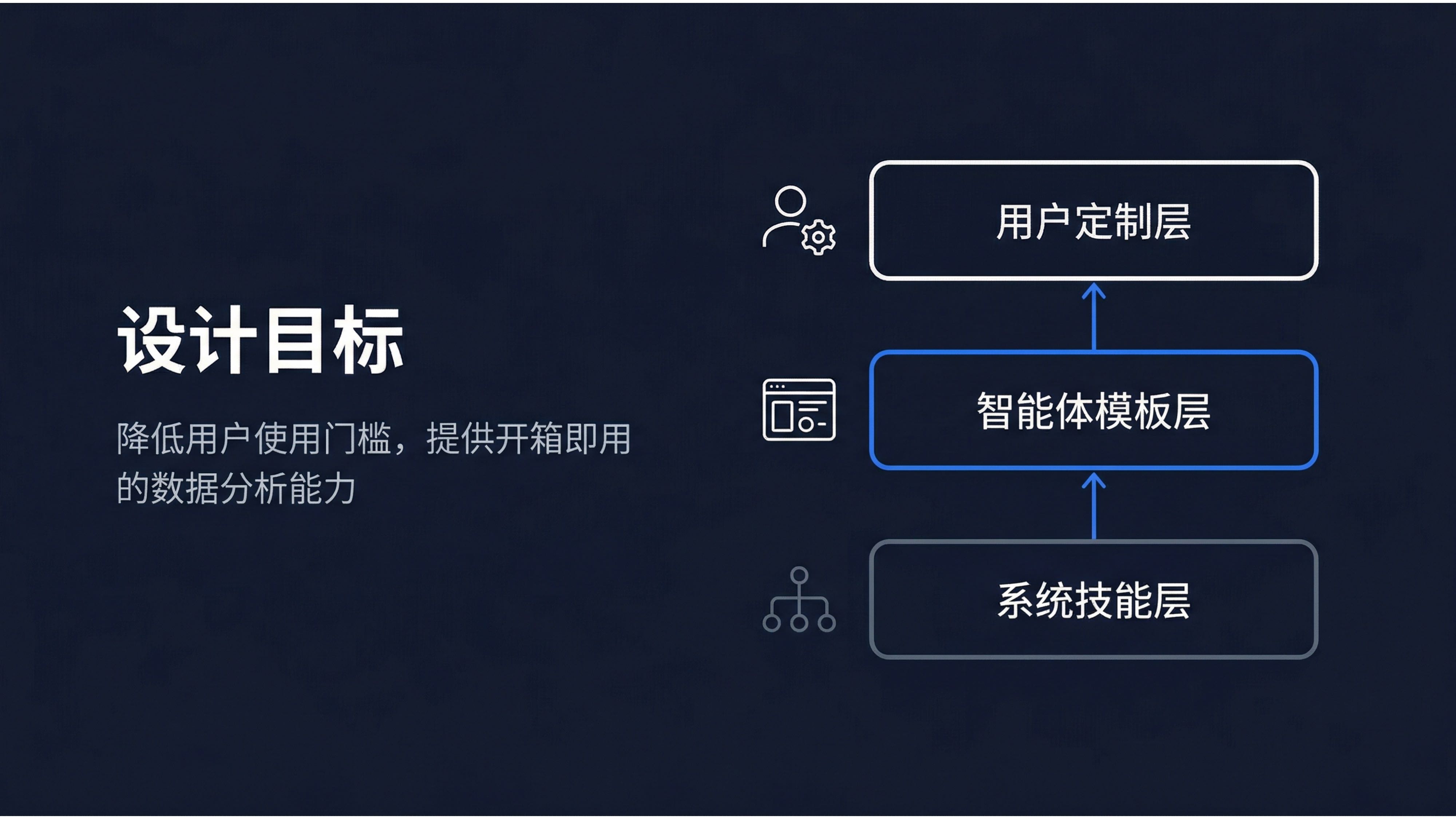
AskTable 的能力封装可以理解为三个递进的层次:
| 层次 | 内容 | 价值 |
|---|---|---|
| L1:技能层 | 11 种内置技能,覆盖数据分析的核心能力 | 让 AI 拥有专业的分析方法论 |
| L2:智能体层 | 9 个行业智能体,组合技能 + 角色 + 业务 | 让 AI 成为"懂行"的虚拟同事 |
| L3:自定义层 | 自定义 Skill + 自定义智能体 | 让企业沉淀自己的专属知识资产 |
这三个层次构成了一个完整的能力封装体系:
L3: 自定义层(企业专属) ← 你的行业知识、分析流程、报告模板
↑
L2: 智能体层(行业通用) ← 9 个行业智能体模板
↑
L1: 技能层(通用能力) ← 11 种内置数据分析技能
企业可以从任何一层开始:
数据分析的未来,不在于培养更多的分析师,而在于把分析师的能力变成每个人触手可及的工具。
AskTable 正在做的事情,就是让这个过程从"定制开发"变成"标准配置"。
