
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家
想象这样一个场景:
周一早上,你问 AI 助手:"上周华东区的销售额怎么样?"它查了数据,告诉你结果。你补充了一句:"以后这种销售数据,帮我按周对比标一下环比变化,我们团队习惯看这个。" AI 说好的。
到了周三,你又问:"华南区这周情况如何?"
然后你发现——它又给了一个干巴巴的数字,没有环比,没有对比。仿佛周一那次对话从未发生过。
这不是一个关于"记性不好"的故事,而是当前绝大多数 AI 数据分析工具的真实写照。
它们每次对话都是从零开始,像一个永远在入职的新员工:你反复解释业务术语,反复纠正输出格式,反复告诉它"我们不看绝对值、看趋势"。它确实聪明,但这种聪明无法积累。
AskTable 正在改变这一点。
通过记忆系统、Skill 系统和行业智能体三大能力的协同,AskTable 正在把 AI 从一个"每次都是新人"的工具,塑造成一个会持续成长的数据团队伙伴。

在数据分析场景中,一个通用 AI 助手面临三个根本性缺陷:
| 断层 | 具体表现 | 用户感受 |
|---|---|---|
| 记忆断层 | 上次说的偏好、纠正的错误、建立的上下文全部丢失 | "每次都要重新教它" |
| 能力断层 | 只能做通用问答,无法执行专业的分析任务 | "它什么都能聊,但什么都不精" |
| 认知断层 | 不理解行业术语、业务逻辑、分析范式 | "它不懂我们这行" |
AskTable 的方案不是在某一个点上修修补补,而是从系统层面构建三个互相支撑的能力支柱:
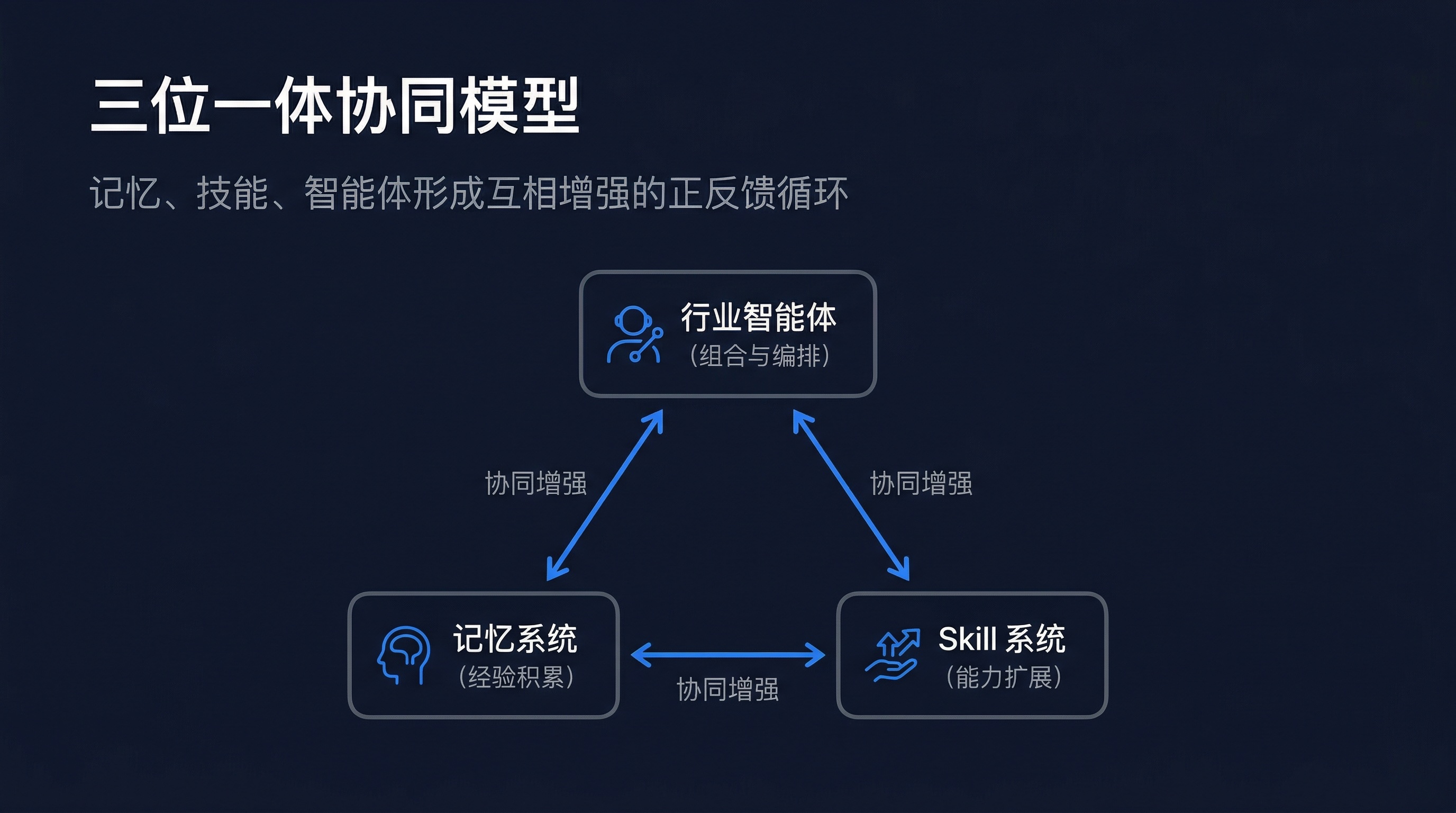
这三个能力不是简单的叠加,而是形成了一个正反馈循环:记忆让智能体更了解用户,Skill 让智能体更有能力,而智能体的使用又反过来产生新的记忆和技能优化。
下面我们逐一拆解这三个支柱。
记忆系统解决的核心问题是:让 AI 在不同会话之间保持连续性。
这不是简单的"保存聊天记录",而是有选择地提取、存储和检索对用户有价值的信息:
记忆系统基于 mem0 + Qdrant 构建,采用读写分离的设计:

关键设计决策:
读写分离:Search 在请求开始时同步执行,Add 在回复完成后异步执行,确保不影响响应速度。
Agent 级隔离:记忆的隔离粒度是 Data Agent 级别,而非用户级别。这意味着同一个 Data Agent(如"销售分析助手")下的所有用户共享记忆,形成团队级的集体记忆。
Protocol 抽象层:记忆系统通过 Protocol 接口定义,mem0 只是当前实现。这确保了未来可以无缝切换到其他记忆方案,而不影响上层逻辑。
LLM 驱动的记忆提取:不是简单保存对话原文,而是通过 LLM 从对话中提取结构化的记忆信息(偏好、事实、纠正),去重后存入向量数据库。
记忆不是简单的"存"和"取",它有完整的生命周期管理:

记忆提取的三种类型:
| 类型 | 示例 | 衰减策略 |
|---|---|---|
| 偏好型 | "我喜欢看环比数据" | 低频衰减,长期保留 |
| 事实型 | "Q1 目标是 5000 万" | 中频衰减,过期自动清理 |
| 反馈型 | "这个分析不需要表格" | 高频衰减,新反馈覆盖旧反馈 |
这种分类确保了记忆系统不会无限膨胀,同时重要的长期偏好能够被持续保留。
记忆系统通过 Protocol 接口定义,而非直接依赖 mem0 的具体实现:
class MemoryProvider(Protocol):
"""记忆提供者协议——确保可替换性"""
async def search(
self,
query: str,
agent_id: str,
limit: int = 5,
) -> list[MemoryEntry]:
"""根据查询检索相关记忆"""
...
async def add(
self,
messages: list[Message],
agent_id: str,
) -> list[MemoryEntry]:
"""从对话中提取并存储新记忆"""
...
async def get_all(self, agent_id: str) -> list[MemoryEntry]:
"""获取 Agent 下的所有记忆"""
...
async def delete(self, memory_id: str) -> bool:
"""删除指定记忆"""
...
# 当前实现:mem0
class Mem0MemoryProvider:
def __init__(self, config: Mem0Config):
self.memory = AsyncMemory.from_config(config)
async def search(self, query, agent_id, limit=5):
results = await self.memory.search(
query=query,
user_id=agent_id,
limit=limit,
)
return [self._to_entry(r) for r in results]
# ... 其他方法实现
这意味着未来如果需要切换到自研记忆方案或其他开源方案,只需实现同一个 Protocol 接口,上层代码无需任何修改。
来看一个对比:
没有记忆系统时:
对话 A(周一):
用户:华东区销售额
AI:1200 万
用户:以后这种数据带上同比和环比
AI:好的
对话 B(周三):
用户:华南区销售额
AI:800 万 ← 没有同比环比
有了记忆系统后:
对话 A(周一):
用户:华东区销售额
AI:1200 万
用户:以后这种数据带上同比和环比
AI:好的 → 记忆系统提取并存储:
"用户偏好:销售数据需包含同比和环比"
对话 B(周三):
用户:华南区销售额
AI:800 万,同比 +12%,环比 -3% ← 自动应用偏好
注:环比下降主要受 XX 品类影响
记忆系统的意义在于:AI 不再需要你反复教它。 它会把每次交互中的有价值信息沉淀下来,在下一次对话中自动调用。
关于记忆系统的技术细节,推荐阅读:AskTable 永久记忆系统:让 AI 记住每一次对话
如果说记忆系统解决了 AI 的"经验积累"问题,那么 Skill 系统解决的则是"专业能力"问题。
传统 Agent 的做法是把所有能力都塞进系统提示词或工具列表。这带来两个问题:
AskTable 的 Skill 系统采用了一种更优雅的方案:项目级技能库 + 热插拔加载。


核心设计要点:
activate_skill() 工具,Agent 可以在对话过程中按需激活技能,扩展自己的能力边界三层加载机制是 Skill 系统的核心创新之一。它确保了在不同场景下,Agent 都能获得最合适的技能集合:
这种设计的意义在于:既不强迫 Agent 每次携带所有技能(避免上下文污染),又能确保在需要时快速获得专业能力。
AskTable 内置了 11 种专业数据分析技能,覆盖了从数据探索到报告生成的完整分析链路:

| 编号 | 技能名称 | 核心能力 | 典型场景 |
|---|---|---|---|
| 01 | 异常检测 | 自动识别数据异动 | 发现销售额突然下降 |
| 02 | 预测趋势 | 基于历史预测走势 | 预估下月营收 |
| 03 | 下钻指标 | 多维度逐层拆解 | 找出问题具体原因 |
| 04 | 对比分析 | 同比/环比/横纵向对比 | 门店业绩排名对比 |
| 05 | 归因分析 | 量化各因素贡献度 | 销售额下降归因 |
| 06 | 预测压力测试 | 多场景模拟推演 | "如果原料涨价 10% 会怎样" |
| 07 | 周期分析 | 识别季节性/周期性模式 | 发现月度/季度规律 |
| 08 | 编排报告 | 自动生成结构化分析报告 | 月度经营汇报 |
| 09 | 指标解读 | 业务视角解读指标含义 | 向非技术人员解释数据 |
| 10 | 数据质量检测 | 自动发现数据异常和缺失 | 监控数据质量 |
| 11 | 业务语言生成 | 将数据结论转为业务语言 | 生成管理层可读的结论 |
这 11 种技能就像是一个分析团队的"标准武器库"——每个技能都是一个专业数据分析师的核心能力。
关于 Skill 系统的深入解析,推荐阅读:AskTable Skill 系统:让 AI Agent 按需调用专业能力
有了记忆和技能,下一步是如何把它们组织成一个"懂行"的专家。这就是行业智能体的价值。
智能体不是简单的技能堆砌,而是针对特定业务场景的技能组合 + 行业知识 + 分析范式的封装。

AskTable 预置了 9 个行业智能体,覆盖了最常见的数据分析场景:
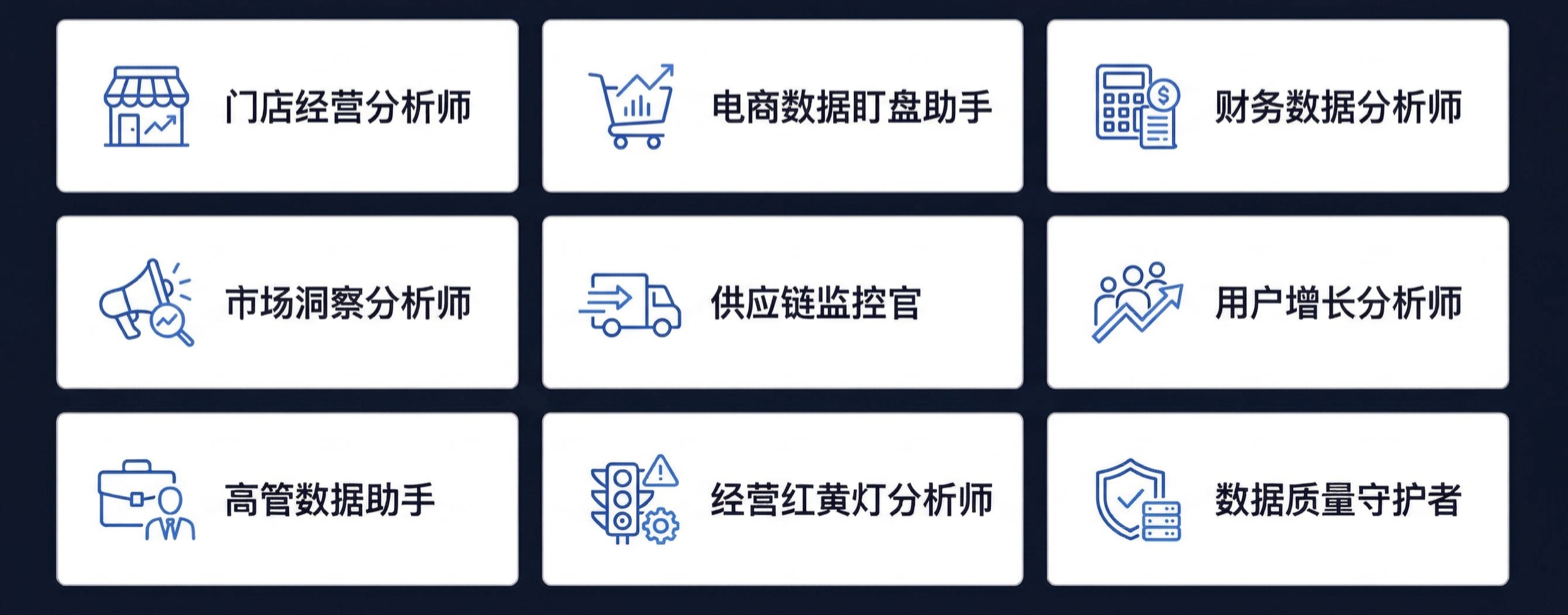
| 智能体 | 定位 | 核心场景 |
|---|---|---|
| 门店经营分析师 | 零售门店业绩监控与分析 | 门店业绩异动检测、品类分析、店长经营建议 |
| 电商数据盯盘助手 | 电商平台数据实时监控 | GMV 追踪、转化率监控、流量来源分析 |
| 财务数据分析师 | 财务报表分析与解读 | 利润表分析、成本结构拆解、预算执行监控 |
| 市场洞察分析师 | 市场趋势与竞争分析 | 市场份额、竞品对标、消费者洞察 |
| 供应链监控官 | 供应链全链路监控 | 库存预警、交付周期分析、供应商评估 |
| 用户增长分析师 | 用户增长与留存分析 | 获客成本、留存曲线、LTV 分析 |
| 高管数据助手 | 管理层数据问答 | 经营指标快速查询、高管看板生成 |
| 经营红黄灯分析师 | 经营健康度预警 | 指标红黄绿灯、风险预警、改善建议 |
| 数据质量守护者 | 数据质量监控与治理 | 异常数据检测、完整性校验、质量报告 |
智能体的核心价值在于理解你的业务语境,自动选择合适的技能组合。
以一个电商运营场景为例:
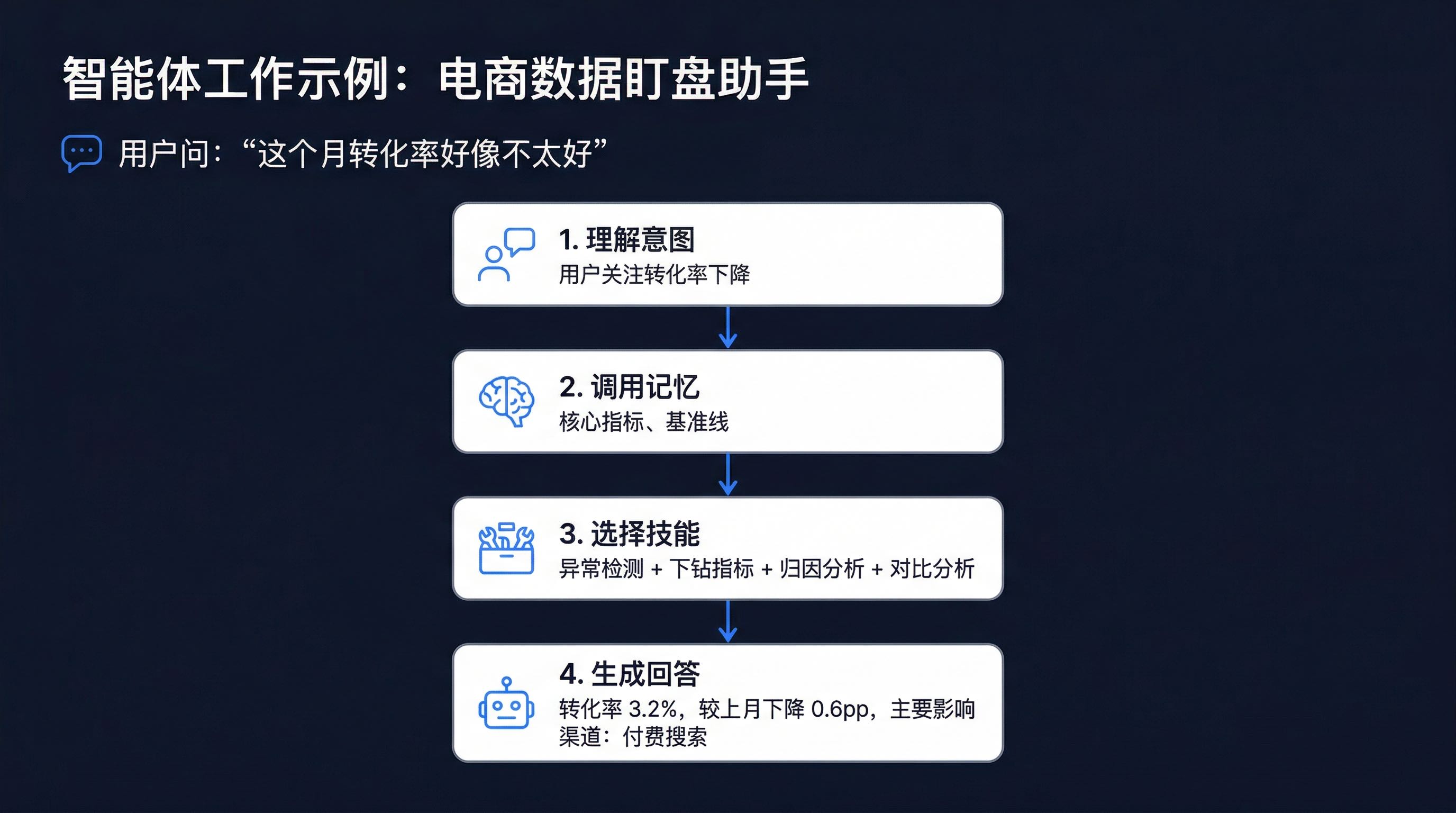
智能体之所以能做到这一点,是因为它:
关于内置技能和智能体的完整介绍,推荐阅读:AskTable 内置技能与智能体:开箱即用的数据分析能力
记忆、技能、智能体三者不是独立工作的,它们形成了一个互相增强的正反馈循环:
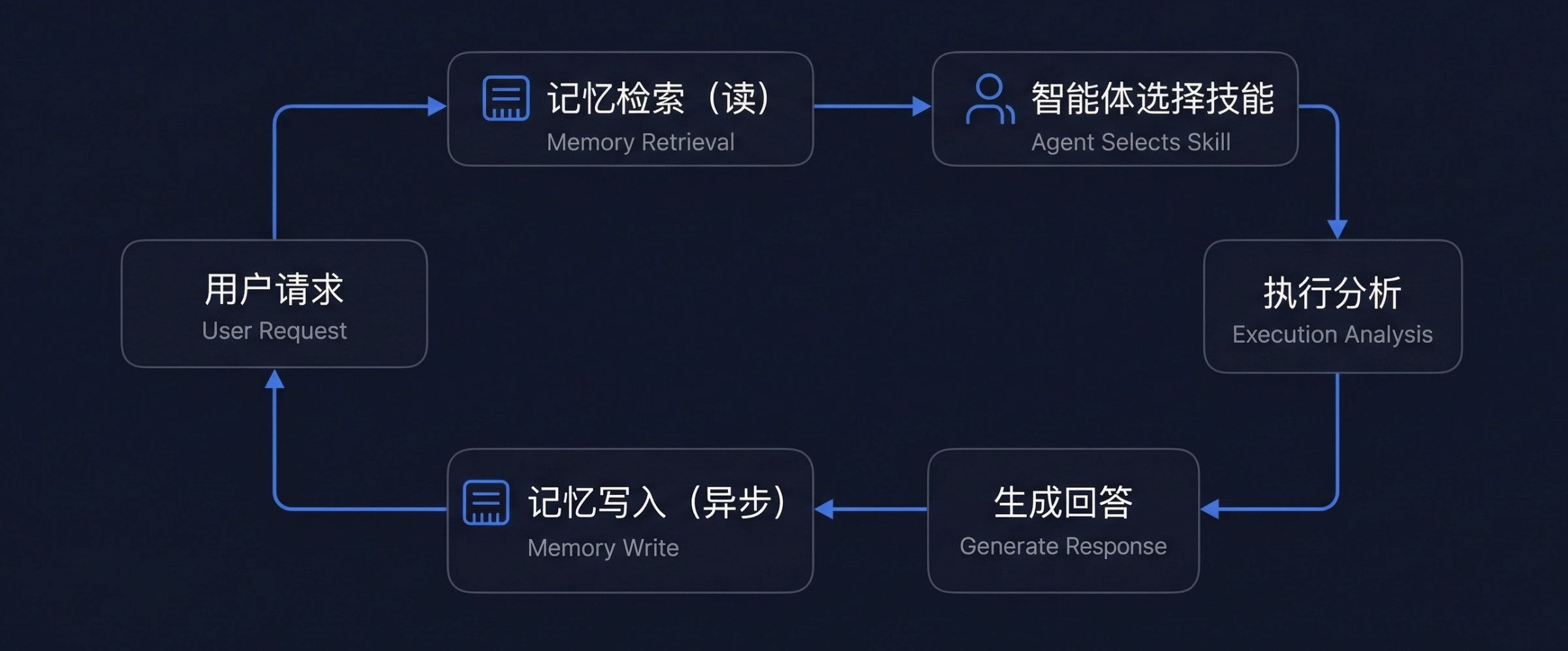
让我们通过一个完整的使用场景,看看三者如何协同工作:
场景:某零售企业运营总监使用 AskTable 进行月度经营分析
═══════════════════════════════════════════════════════════════
第 1 步:用户发起请求
───────────────────────────────────────────────────────────────
用户:"帮我看看上个月的经营情况"
═══════════════════════════════════════════════════════════════
第 2 步:记忆系统介入(读)
───────────────────────────────────────────────────────────────
记忆检索发现:
✓ 该用户的 Data Agent 是「高管数据助手」
✓ 用户偏好:关注营收、利润率、同比环比
✓ 上次纠正:"环比用上月对比,不要用移动平均"
✓ 业务上下文:Q1 营收目标 5000 万,当前完成 62%
→ 这些信息被注入到系统提示词中
═══════════════════════════════════════════════════════════════
第 3 步:智能体选择技能
───────────────────────────────────────────────────────────────
「高管数据助手」智能体分析用户需求后,决定激活以下技能:
activate_skill("周期分析") → 识别上月整体趋势
activate_skill("对比分析") → 同比、环比、目标达成
activate_skill("异常检测") → 检查是否有异常波动
activate_skill("下钻指标") → 定位主要增长/下滑来源
activate_skill("业务语言生成") → 生成管理层可读结论
═══════════════════════════════════════════════════════════════
第 4 步:执行分析
───────────────────────────────────────────────────────────────
AI 按顺序执行各技能,生成结构化分析:
📊 上月经营摘要
━━━━━━━━━━━━━━━━━━━━━━━━
营收:1,850 万 | 同比 +15% | 环比 +8%
利润率:18.5% | 同比 +1.2pp | 环比 -0.3pp
Q1 目标达成率:62%(进度正常)
📈 关键发现:
01. 营收增长主要受华东区新品驱动(贡献率 65%)
02. 利润率环比微降,主要受原材料成本上涨影响
03. 华南区业绩异常偏低(低于均值 2.1 个标准差)
⚠️ 风险提示:
华南区连续两周下滑,建议关注
═══════════════════════════════════════════════════════════════
第 5 步:用户交互与反馈
───────────────────────────────────────────────────────────────
用户:"华南区那个异常,帮我重点看看是哪几个店的问题"
→ 记忆系统记录用户的关注焦点
→ 智能体激活「下钻指标」和「异常检测」技能
→ 生成详细分析
═══════════════════════════════════════════════════════════════
第 6 步:记忆系统写入(异步)
───────────────────────────────────────────────────────────────
对话结束后,记忆系统异步执行:
✓ 提取:用户重点关注异常门店
✓ 提取:用户对华南区业绩持续跟踪
✓ 更新:华南区为当前重点关注区域
→ 下次对话时,AI 会主动关注华南区情况
═══════════════════════════════════════════════════════════════
这套系统的核心优势在于它是一个会自我增强的正反馈循环:
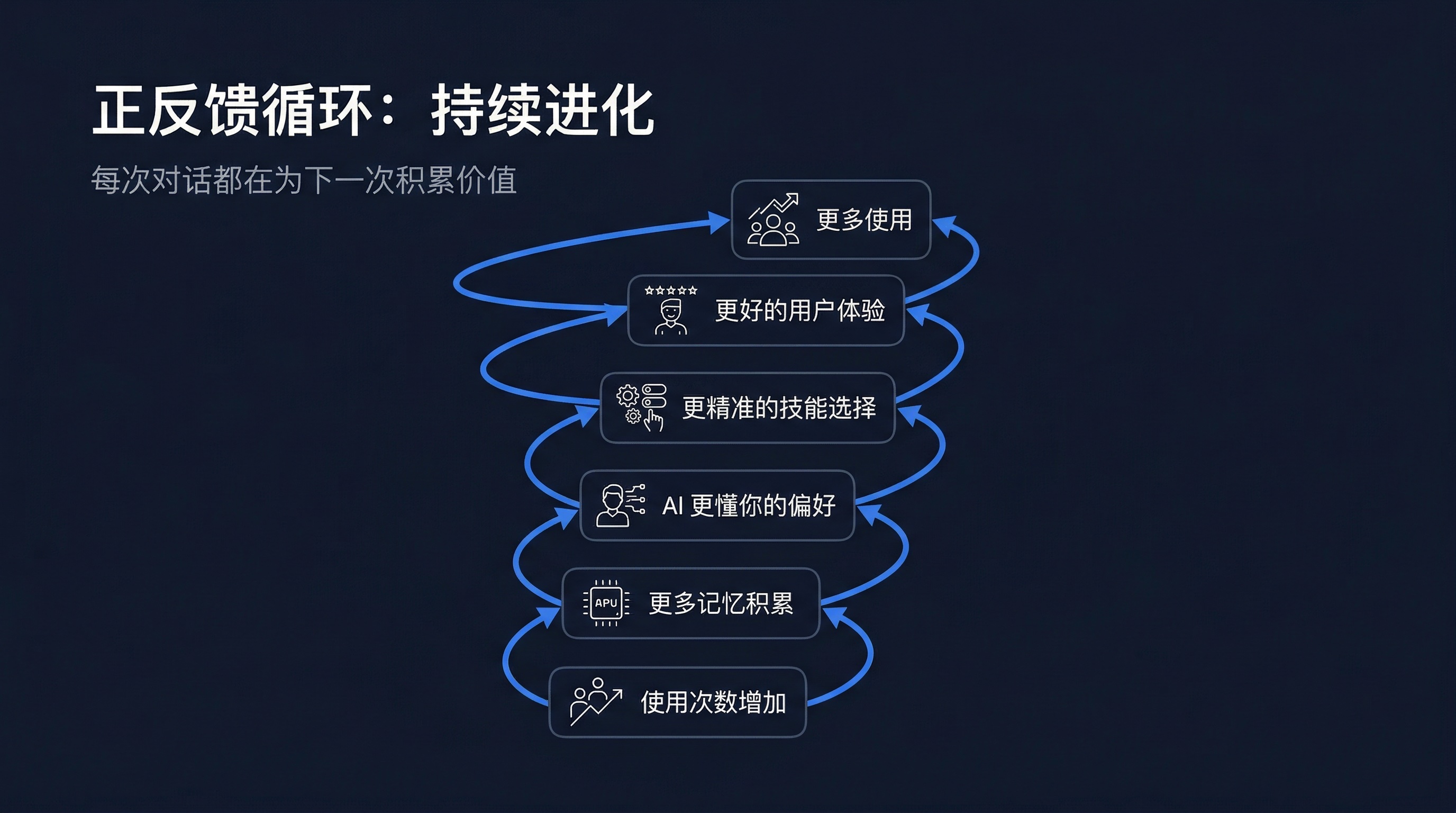
每一次对话都在为下一次对话积累价值。这就是"会成长的团队"的真正含义。
某中型零售企业(年营收约 2 亿),使用 AskTable 三个月后的变化:
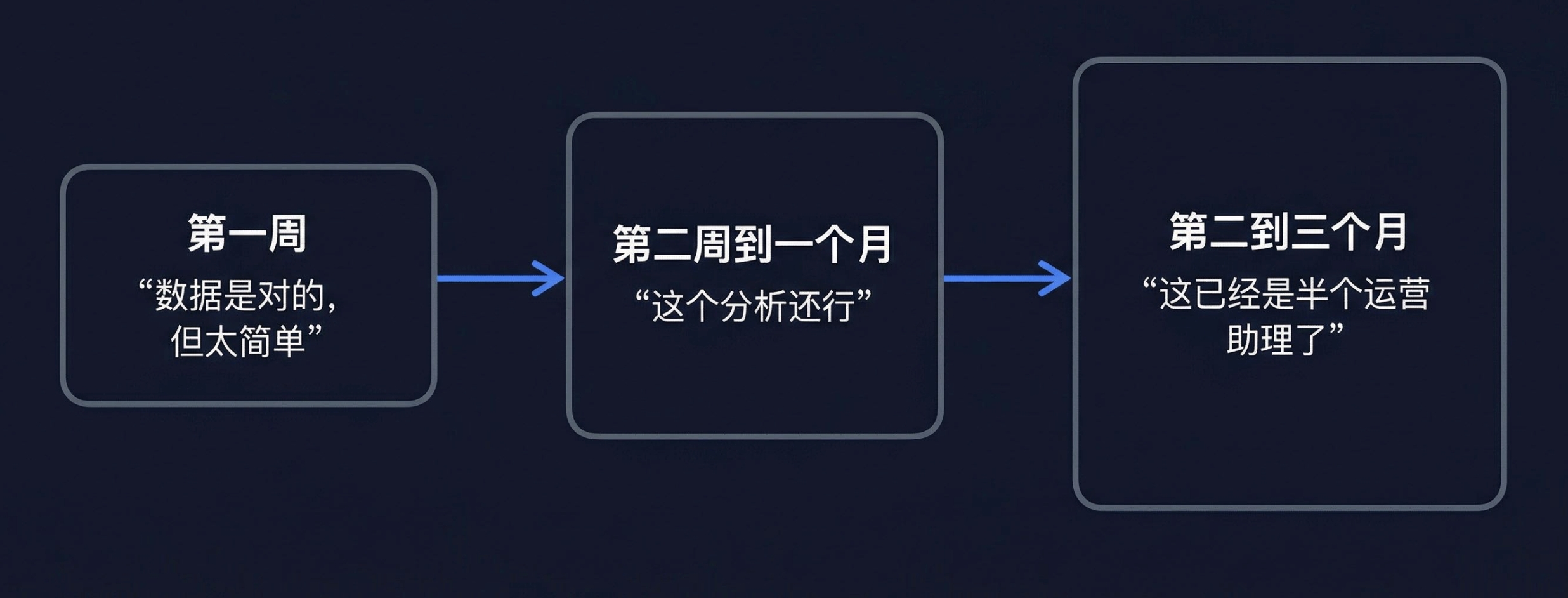
第一周:工具阶段
运营总监李明第一次使用 AskTable,把它当作一个"能查数据的聊天机器人"。
李明:"上个月各区域的销售额"
AI: "华东 580 万,华南 320 万,华北 410 万,西南 190 万"
李明:(心里想)嗯,数据是对的,但太简单了
此时的 AI,和一个会写 SQL 的实习生差不多。
第二周到一个月:学习阶段
李明开始给 AI 反馈:
李明:"以后这种数据,帮我标一下同比和环比"
AI: "好的"
李明:"华南这个月怎么这么差?"
AI: (调用异常检测 + 下钻分析)
"华南区 320 万,环比下降 22%,同比下降 8%
主要拖累:广州天河店(-45%)、深圳南山店(-31%)
共性:两个店都有装修停业天数"
李明:(心里想)这个分析还行
记忆系统开始工作——李明的偏好、关注区域、分析习惯被记录下来。
第二到三个月:同事阶段
李明:"这个月经营情况"
AI: "📊 3月经营快报
━━━━━━━━━━━━━━━
营收 1,850 万,同比 +15%,环比 +8%
利润率 18.5%,同比 +1.2pp
Q1 目标达成 62%,进度正常
📈 亮点:
华东区新品系列拉动营收增长 12%
⚠️ 关注:
华南区仍在恢复中,但环比已回升 5%
(你上月关注的天河店已恢复正常营业)
需要我出一份详细的月度经营报告吗?"
李明:(心里想)这已经是半个运营助理了
此时的 AI:
这就是从"工具"到"同事"的蜕变。
| 维度 | 使用初期 | 使用三个月后 |
|---|---|---|
| 平均每次查询轮次 | 4-6 轮 | 1-2 轮 |
| 月度经营报告生成时间 | 半天 → 3 分钟 | 1 分钟(AI 主动生成) |
| 数据异常发现时间 | 周会时发现 | 当天主动预警 |
| 李明对 AI 的信任度 | "需要复核它的数据" | "基本可以直接用" |
记忆系统存储的信息会直接影响智能体对 Skill 的选择:
# 伪代码:记忆增强技能选择
async def select_skills_with_memory(agent, user_query):
# 1. 从记忆系统检索相关上下文
memories = await memory.search(user_query, agent_id=agent.id)
# 2. 将记忆注入提示词
enhanced_prompt = build_prompt(
base_prompt=agent.system_prompt,
memories=memories, # 包含用户偏好和历史关注点
)
# 3. Agent 基于增强后的提示词选择技能
selected_skills = await agent.decide_skills(
query=user_query,
prompt=enhanced_prompt,
)
# 4. 激活选中的技能
for skill in selected_skills:
await agent.activate_skill(skill)
return selected_skills
Skill 的执行结果和用户反馈会成为新的记忆:
用户问:"帮我看看上月经营情况"
│
├── AI 调用多项技能生成报告
│
├── 用户反馈:"华南区的数据我想每周都看"
│ │
│ └── 记忆系统提取:
│ "用户希望每周跟踪华南区数据"
│
└── 下次用户问经营情况时
│
└── AI 主动包含华南区周报分析
智能体是整个系统的"大脑",负责:
┌─────────────────────────────────────────────────┐
│ 智能体调度流程 │
│ │
│ 收到用户请求 │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 理解用户意图 │ │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 检索记忆上下文 │ ← 读记忆 │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 选择关联技能 │ ← 用 Skill │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 执行分析并回复 │ │
│ └────────┬────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────┐ │
│ │ 异步写入新记忆 │ ← 写记忆 │
│ └─────────────────┘ │
│ │
└─────────────────────────────────────────────────┘
传统的数据分析工具,本质上都是**"查询引擎"**——你输入问题,它返回数据。每次交互都是独立的,没有积累,没有成长。
AskTable 的思路是把 AI 数据分析变成一个**"成长中的团队"**:
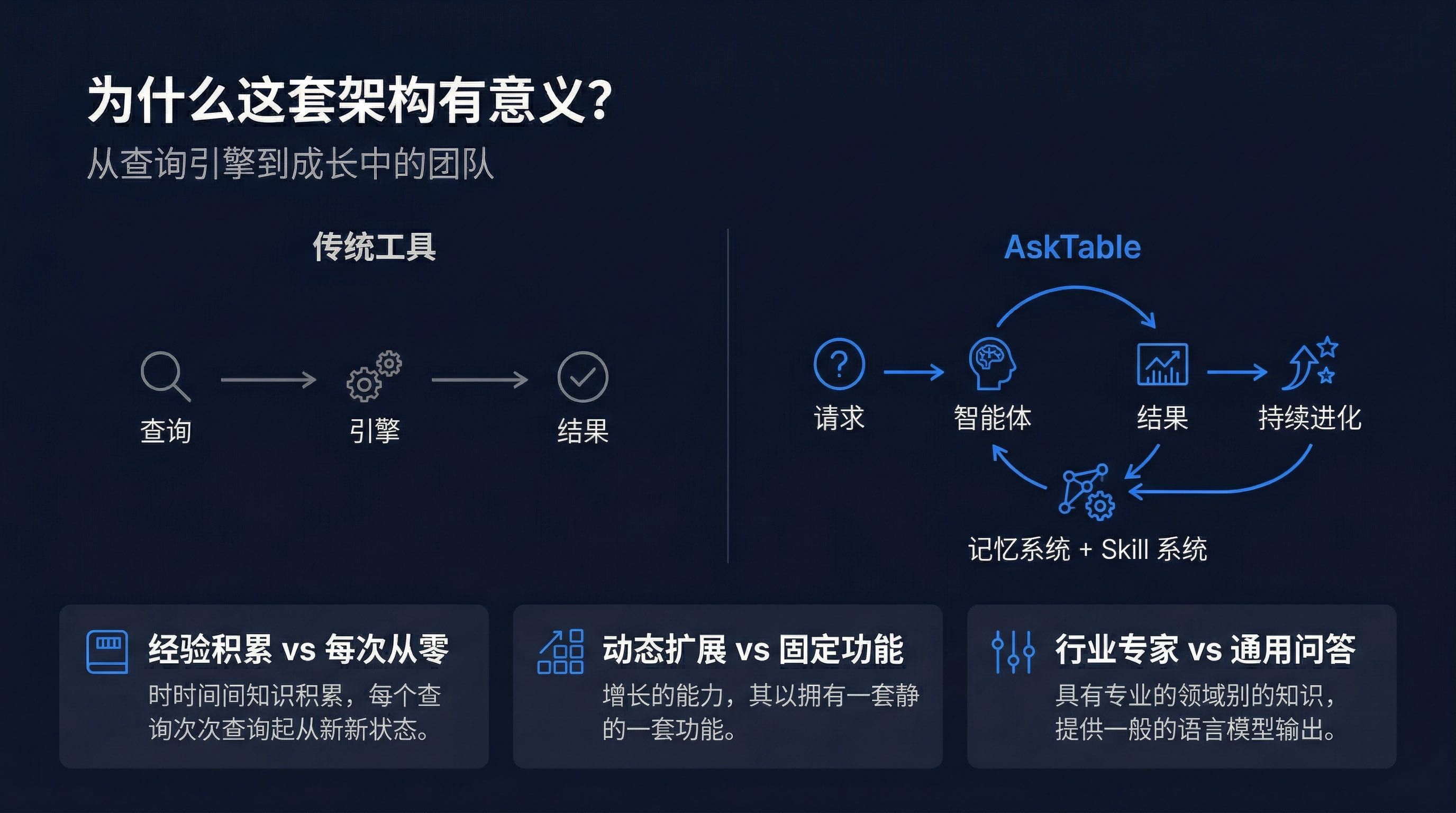
| 维度 | 传统工具 | AskTable |
|---|---|---|
| 经验 | 每次从零开始 | 跨会话积累,越用越懂你 |
| 能力 | 固定功能集 | 动态扩展,按需调用 |
| 认知 | 通用问答 | 行业专家,懂业务语境 |
这套架构的设计哲学是开放和可扩展:
这意味着,AskTable 的能力边界不是固定的,而是随着使用持续扩展的。
"好的 AI 工具不是越来越聪明,而是越来越懂你。"

回顾 AskTable 的三大核心能力:
记忆系统:让 AI 不再失忆。通过 mem0 + Qdrant 的读写分离设计,在 Data Agent 级别积累团队级的集体记忆。
Skill 系统:让 AI 拥有专业能力。项目级技能库 + 热插拔加载 + 11 种内置技能,覆盖从异常检测到报告生成的完整分析链路。
行业智能体:让 AI 懂行。9 大智能体将技能组合成面向具体业务场景的分析能力,开箱即用。
三者协同工作,形成了一个持续进化的正反馈循环——记忆让智能体更懂用户,技能让智能体更有能力,而智能体的每一次使用都在产生新的记忆和技能优化。
这不是在做一个更好的查询工具,而是在构建一个会成长的数据分析团队。
