
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家
2025 年到 2026 年,几乎所有中大型企业的 CTO 和 CIO 都面临同一个问题:
"我们的 AI 项目,到底该怎么落地?"
在过去两年的调研中,我们发现企业 AI 落地几乎都陷入一个"不可能三角"——
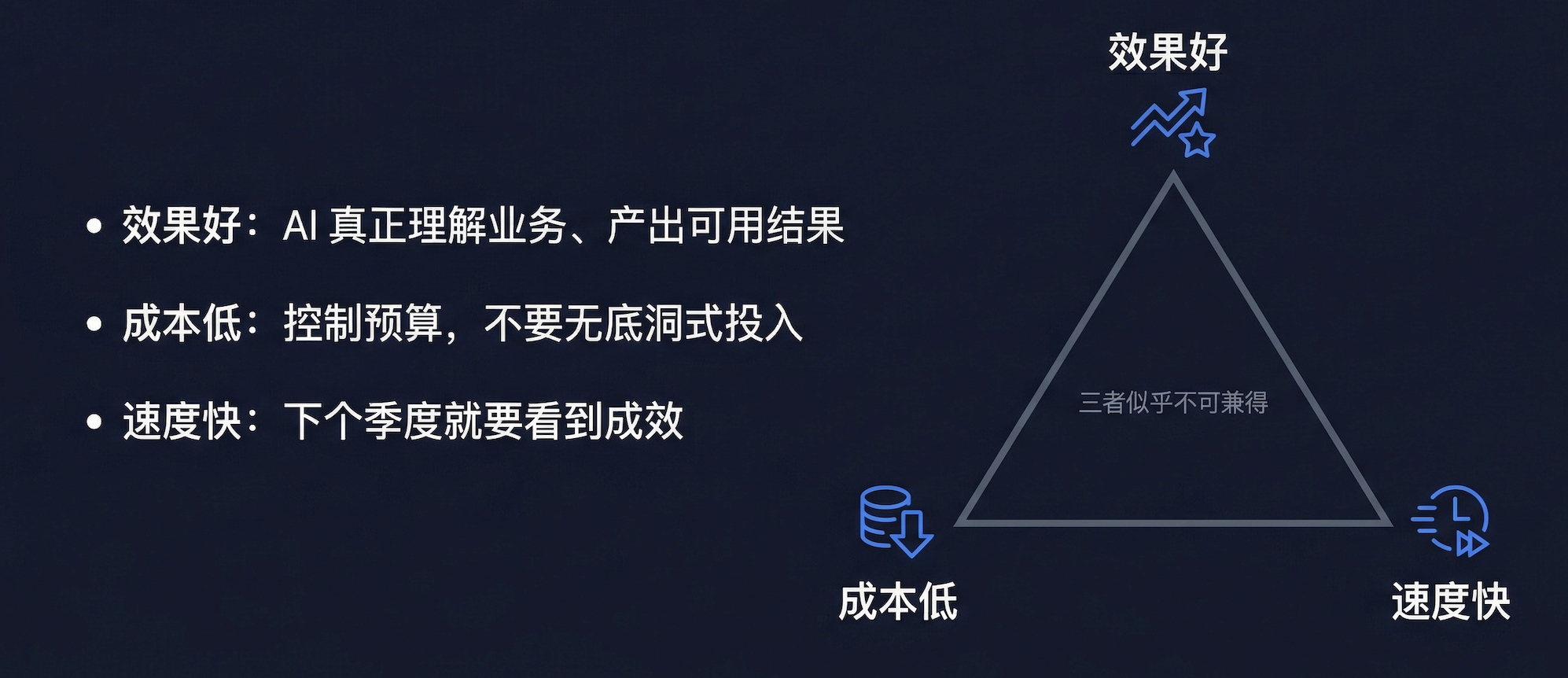
这三者似乎不可兼得。于是企业通常会在两条路之间做选择,但每条路都有自己的困境。
今天,我们想从战略视角探讨第三条路——不是自建大模型,不是从零开发 Agent 框架,而是做能力编排:以顶级大模型为引擎,通过成熟的技能系统和智能体模板,快速组合出符合企业业务需求的数据分析能力。

这条路上,AskTable 已经跑通了一些头部企业的验证案例。本文将拆解这条路的逻辑、架构和选型方法。
自建大模型的诱惑很直接:
于是很多企业的 AI 路线图是这样的:组建 AI 团队 → 采集行业数据 → 训练或微调模型 → 部署上线 → 持续迭代。
我们接触过多家尝试或正在自建大模型的企业,发现沉没成本主要来自以下几个维度:

第一,人才成本被严重低估。
训练和维护一个大模型,需要的不只是算法工程师。一个完整的团队通常包括:
这样的团队在一线城市的年度人力成本通常在 800 万到 1500 万元之间。更重要的是,这些人才在市场上极度稀缺,招人周期通常在 6-12 个月。
第二,算力投入像无底洞。
一次完整的大模型训练,从数据准备到模型收敛,算力投入动辄 数百万到上千万。即使选择微调现有开源模型(如 Qwen、LLaMA),也需要 GPU 集群支撑。
更关键的是,这不是一次性投入——模型需要持续更新,数据需要持续标注,效果需要持续评估。
第三,效果不及预期的风险。
即使投入了人才和算力,最终产出的行业模型在很多场景下的效果,可能并不比调用一个顶级 API 好多少。原因很简单:通用大模型的能力迭代速度,远快于企业自建模型的迭代速度。
当你花半年微调出一个模型,基座模型可能已经迭代了两到三个大版本,能力差距又拉开了。
自建大模型不是不能做,而是只适合少数有长期战略投入能力和人才储备的头部企业。对于绝大多数企业来说,这是一条投入大、周期长、风险高的路。
既然自建大模型成本太高,很多企业选择了第二条路:接入开源 Agent 框架(如 LangChain、AutoGen、CrewAI 等),基于现有大模型 API 构建自己的智能应用。
这条路听起来很合理——不需要养 AI 团队,不需要买算力,只需要几个开发工程师就能搞定。
但现实往往比想象复杂。
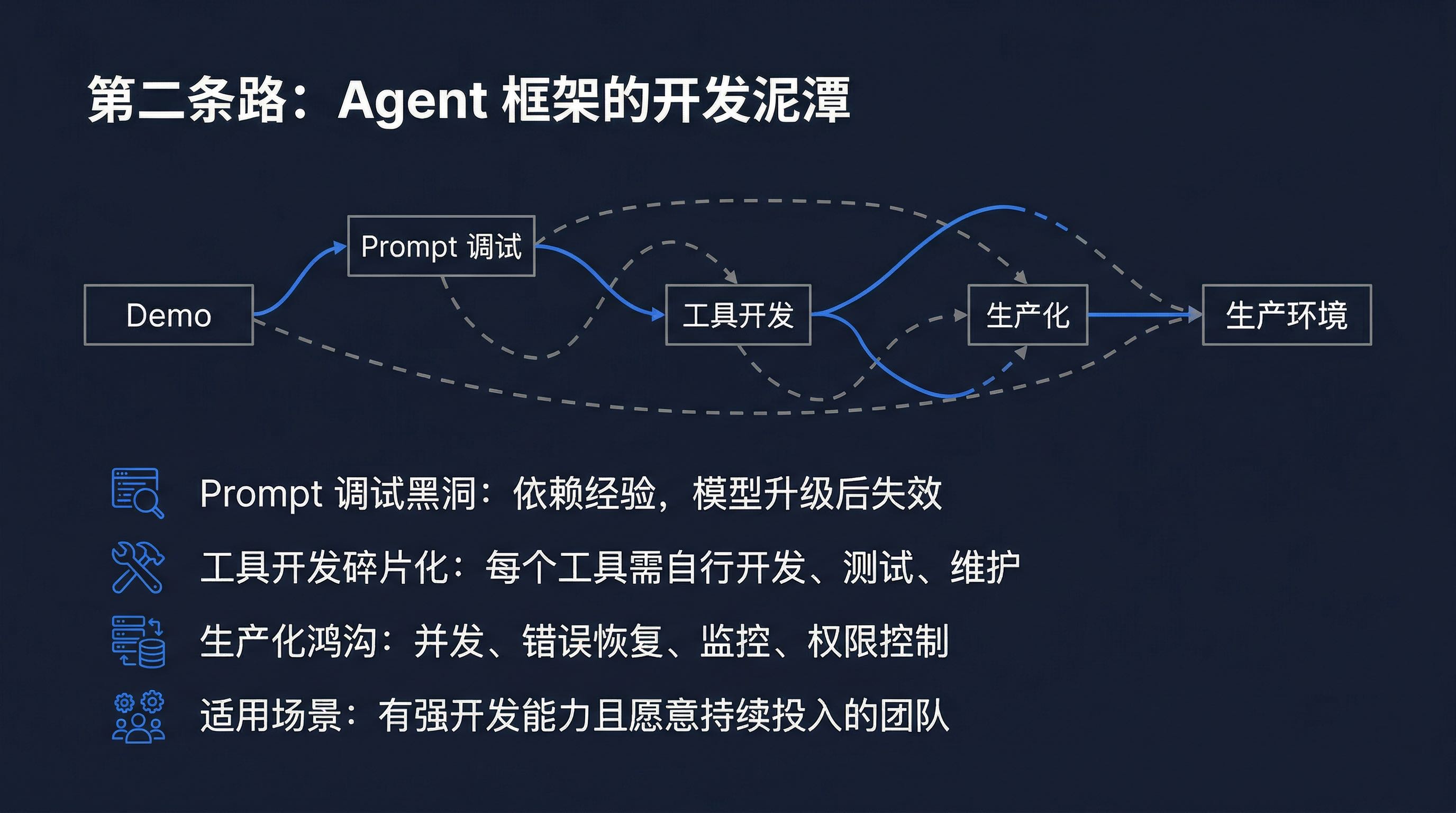
第一,Prompt 调试的黑洞。
Agent 框架的核心是 Prompt 工程。但 Prompt 调试是一个极度依赖经验的黑盒过程:
很多团队花了几周甚至几个月的时间在 Prompt 调试上,最后发现效果仍然不稳定。
第二,工具开发的碎片化。
Agent 框架提供了架构,但每个工具(Tool)都需要自己开发。比如:
每个工具的开发、测试、维护都需要投入,而且工具之间的协作逻辑也需要自己设计。
第三,生产化的鸿沟。
从 Demo 到生产环境,中间隔着巨大的鸿沟:
这些问题在 Agent 框架的文档里找不到现成答案,都需要自己解决。
Agent 框架降低了对 AI 专业知识的要求,但大幅提高了对工程能力的要求。它适合有强开发能力、愿意持续投入调试和维护的团队。但对于想要"开箱即用"的企业来说,这同样是一条充满不确定性的路。
能力编排的核心思路是:不把精力花在造轮子上,而是把顶级能力组合起来,形成面向业务场景的完整解决方案。

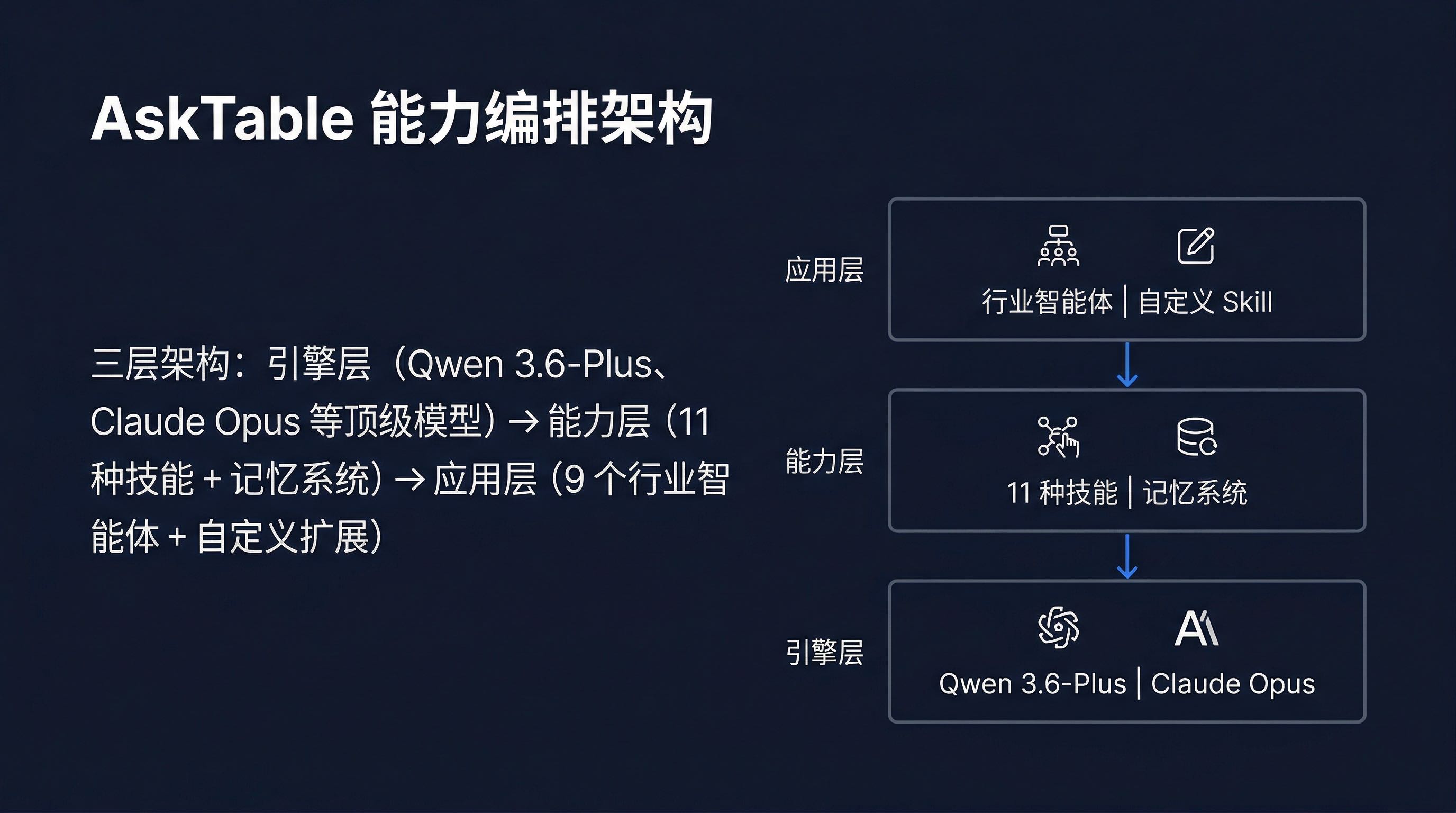
具体来说,包含三个层次:
┌──────────────────────────────────────────────────┐
│ 应用层(面向业务) │
│ 行业智能体模板 | 自定义 Skill | 对话式分析界面 │
├──────────────────────────────────────────────────┤
│ 能力层(核心编排) │
│ 11种技能 | 记忆系统 | 工具系统 | 知识检索 │
├──────────────────────────────────────────────────┤
│ 引擎层(模型驱动) │
│ Qwen 3.6-Plus | Claude Opus | 其他顶级模型 │
└──────────────────────────────────────────────────┘
引擎层不需要你自建,直接接入 Qwen 3.6-Plus、Claude Opus 4.5 等顶级模型即可。这些模型的能力迭代速度远超任何企业自建团队。
能力层提供了一套标准化的技能系统——异常检测、归因分析、预测趋势、数据可视化等,这些都是数据分析领域通用的核心能力,已经经过了大量实际场景的验证。
应用层则基于能力层的技能,组合出面向不同行业的智能体模板,企业可以直接使用或在此基础上定制。
能力编排之所以能成为第三条路,核心在于它解决了前两条路各自的痛点:
对比自建大模型:
对比 Agent 框架开发:
能力编排这条路能走通,有一个重要的行业背景:顶级大模型之间的能力差距正在缩小。
以 Qwen 3.6-Plus 为例,其编程能力相比上一代提升了 2-3 倍,在代码生成、数据分析和复杂推理等场景下,已经可以媲美甚至超越部分国际顶级模型。
这意味着,企业在选择模型时,不再需要纠结于"哪个模型最好",而是可以基于成本、合规、响应速度等实际因素灵活选择。真正拉开差距的,不是模型本身,而是如何将模型能力编排成面向业务的完整解决方案。
这也正是能力编排的价值所在。
AskTable 的引擎层支持多种大模型,包括但不限于:
引擎层的设计哲学是"模型即插即用"——企业可以根据成本、性能、合规要求选择最适合的模型,而不影响上层能力的运行。
更重要的是,当底层模型升级时,上层能力自动受益。比如 Qwen 3.6-Plus 发布后,所有使用 Qwen 引擎的 AskTable 智能体自动获得更强的编程和分析能力,无需任何代码改动。
能力层是 AskTable 的核心竞争力,它包含了11 种经过实战验证的数据分析技能:
| 技能 | 能力说明 | 典型场景 |
|---|---|---|
| 异常检测 | 自动识别数据中的异常点和离群值 | 生产质量监控、交易异常发现 |
| 归因分析 | 分析指标变化的根本原因 | 销售下降分析、成本波动溯源 |
| 预测趋势 | 基于历史数据预测未来趋势 | 销售预测、库存规划 |
| 数据清洗 | 自动处理缺失值、重复值、格式问题 | 多源数据整合 |
| 统计分析 | 描述性统计、假设检验、相关性分析 | 市场调研分析 |
| 对比分析 | 多维度对比,发现差异模式 | 竞品对比、区域差异分析 |
| 聚类分析 | 自动分组,发现数据内在结构 | 客户分群、产品归类 |
| 关联分析 | 发现变量之间的关联关系 | 购物篮分析、行为关联 |
| 数据可视化 | 自动选择最优图表类型并生成 | 报表生成、数据展示 |
| SQL 生成 | 自然语言转 SQL,自动化查询 | 非技术人员自助取数 |
| 报告生成 | 自动撰写结构化分析报告 | 日报、周报、月报 |
这些技能不是简单的功能列表,而是经过大量场景验证、经过精心调优、可以稳定复用的能力模块。
关于 AskTable 技能系统的详细设计,可以参考我们的深度解析:AskTable Skill 系统:让 AI 智能体拥有专业数据分析能力。
记忆系统:让智能体"记住"经验
除了技能之外,AskTable 还实现了永久记忆系统,让智能体能够:
这意味着,智能体不是一次性工具,而是会随着使用时间增长而越来越"懂你"的数据分析伙伴。
关于记忆系统的技术实现,详见:AskTable 永久记忆系统:让 AI 记住每一次交互。
基于能力层的技能组合,AskTable 提供了9 个开箱即用的行业智能体,覆盖制造、金融、零售、医疗、教育、能源、物流、互联网、政务等主要行业。
每个行业智能体都针对特定行业的数据结构、分析场景和决策习惯进行了优化。例如:
同时,AskTable 支持自定义 Skill——企业可以根据自己的业务需求,开发专属技能模块,与内置技能无缝集成。
关于内置技能和智能体的完整清单和使用指南,请参考:AskTable 内置技能与智能体清单。
能力编排的核心逻辑可以用一句话概括:
用最好的模型(引擎层)驱动最成熟的技能(能力层),组合出最贴合业务的解决方案(应用层)。
这种架构的优势在于:
从 Agent 架构 的角度来看,AskTable 的设计确保了每个模块的边界清晰、职责明确,这正是能力编排能够落地的技术基础。
企业在选择 AI 落地路径时,建议从以下维度进行评估:
| 评估维度 | 自建大模型 | Agent 框架开发 | 能力编排(AskTable) |
|---|---|---|---|
| 初始投入 | 1000万+ | 50-200万 | 10-50万 |
| 部署周期 | 1-3年 | 3-6个月 | 2-4周 |
| 人才要求 | AI 团队(10人+) | 开发工程师(3-5人) | 业务人员 + IT 配合 |
| 维护成本 | 极高(持续投入) | 高(持续调试) | 低(平台负责) |
| 效果稳定性 | 取决于团队能力 | 波动较大 | 稳定 |
| 模型迭代红利 | 需要主动跟进 | 需要适配新版本 | 自动受益 |
| 行业适配速度 | 慢 | 中等 | 快 |
你的企业是否具备以下条件?
│
├── 有 5000万+ 的 AI 专项预算?
├── 有 10人+ 的 AI 专业团队?
├── 有 2年以上的 AI 建设时间窗口?
├── 有明确的行业模型差异化诉求?
│
└── 如果以上都是 YES → 可以考虑自建大模型
│
否则:
│
├── 你的企业是否有 5人+ 的全栈开发团队?
├── 是否愿意投入 3-6个月进行 Agent 开发和调试?
├── 是否能接受效果波动和持续维护?
│
└── 如果以上都是 YES → 可以尝试 Agent 框架开发
│
否则:
│
└── 能力编排(AskTable)是你的最优选择
- 2-4周部署
- 开箱即用
- 稳定可靠
- 持续享受模型迭代红利
即使是有能力自建大模型的企业,我们也建议先用能力编排跑通业务场景,验证价值,再考虑是否需要自建模型。
原因很简单:能力编排让你在几周内就能看到 AI 在业务场景中的实际效果,而自建模型需要一两年才能看到成果。用实际效果来指导战略决策,比用战略想象来指导技术投入,要靠谱得多。
回顾企业 IT 的发展历史,你会发现一个规律:
但最终,企业真正关心的从来不是底层技术选型,而是如何用这些技术解决业务问题。
大模型和云基础设施一样,正在走向同质化和 commoditization(商品化)。未来企业的核心竞争力,不在于用了哪个模型,而在于如何将模型能力编排成面向业务的完整解决方案。
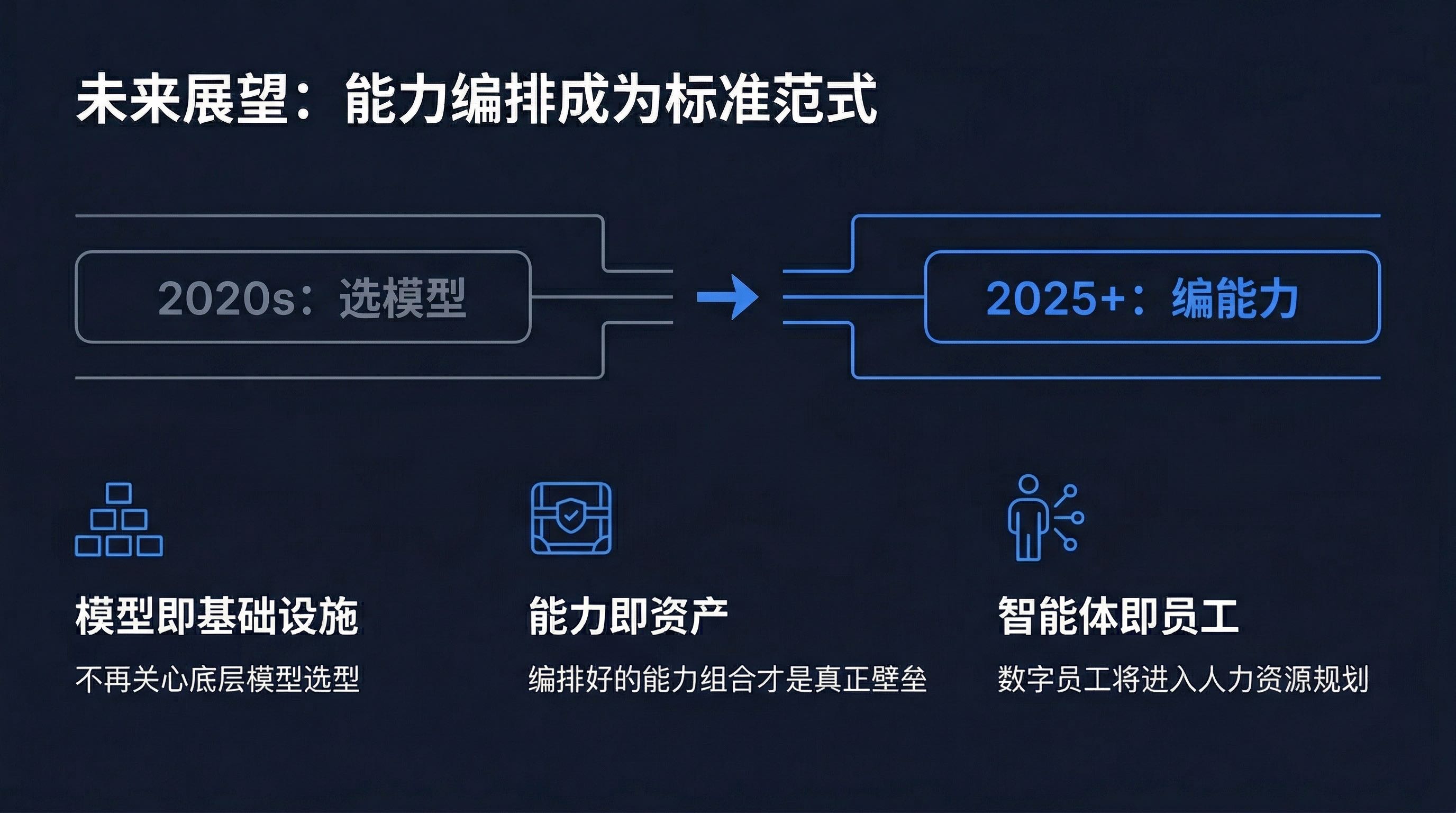
基于对行业的观察,我们预判未来 3-5 年会出现三个趋势:
趋势一:模型即基础设施。
企业不再需要关心底层用的是什么模型,就像现在不需要关心数据库用的是哪个版本一样。模型能力的差异会缩小,接入成本会降低,切换变得无缝。
趋势二:能力即资产。
企业的 AI 资产不再是"训练好的模型",而是"编排好的能力组合"——哪些技能、如何组合、适配什么场景,这些才是真正有壁垒的东西。
趋势三:智能体即员工。
行业智能体会越来越像"数字员工"——有自己的专业技能、工作经验、学习能力,能够独立完成特定岗位的数据分析工作。企业的人力资源规划中,会开始出现"数字员工"的编制。
AskTable 正在沿着能力编排的方向持续深耕:
我们的愿景是:让每一家企业都能以最低的成本、最快的速度,拥有世界级的数据分析能力。
企业 AI 落地从来不是非此即彼的选择题。
自建大模型有它的价值,Agent 框架有它的适用场景。但对于绝大多数想要快速看到 AI 价值、又不想在基础设施上过度投入的企业来说,能力编排是一条务实、高效、可持续的路。
这条路的本质是:用别人的引擎,编自己的能力,解自己的问题。
当你的竞争对手还在为自建模型招兵买马、为 Agent 调试焦头烂额时,你已经用能力编排跑通了业务场景、拿到了业务结果。
这大概就是企业 AI 落地最聪明的走法。
