
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家
2026 年春天,AI Agent 的能力边界正在以肉眼可见的速度扩张。
Claude Code 已经可以独立完成仓库级的代码修改和测试,OpenClaw 凭借开源生态拥有 6000+ 插件,Qwen 3.6-Plus 的编程能力接近 Claude Opus 4.5——从评测数据来看,AI Agent 似乎已经无所不能。

但如果你把这些 Agent 放到真实的企业数据场景中,会发现一个矛盾的现象:
Agent 能写出完美的代码,却回答不好一个看似简单的数据问题。
"上个月华东区销售额同比变化多少?" "哪个产品线的用户留存率下降了?" "帮我对比一下这三个月的运营数据趋势。"
这些问题的答案明明就在企业的数据库里,但 AI Agent 却无从下手。这不是 Agent 不够聪明,而是它缺少了最关键的东西——企业数据的"地图"。

AI Agent 之所以在代码生成和任务规划上表现出色,是因为它有完整的上下文:
但在面对企业数据时,Agent 面临的是一个完全黑盒的环境:
| Agent 知道 | Agent 不知道 |
|---|---|
| 代码仓库有哪些文件 | 企业有哪些数据源 |
| 函数的参数和返回值 | 数据表有哪些字段 |
| API 的调用方式 | 数据的质量和可信度 |
| 依赖包的功能 | 业务术语的真实含义 |
| 测试用例的预期 | 谁能访问什么数据 |
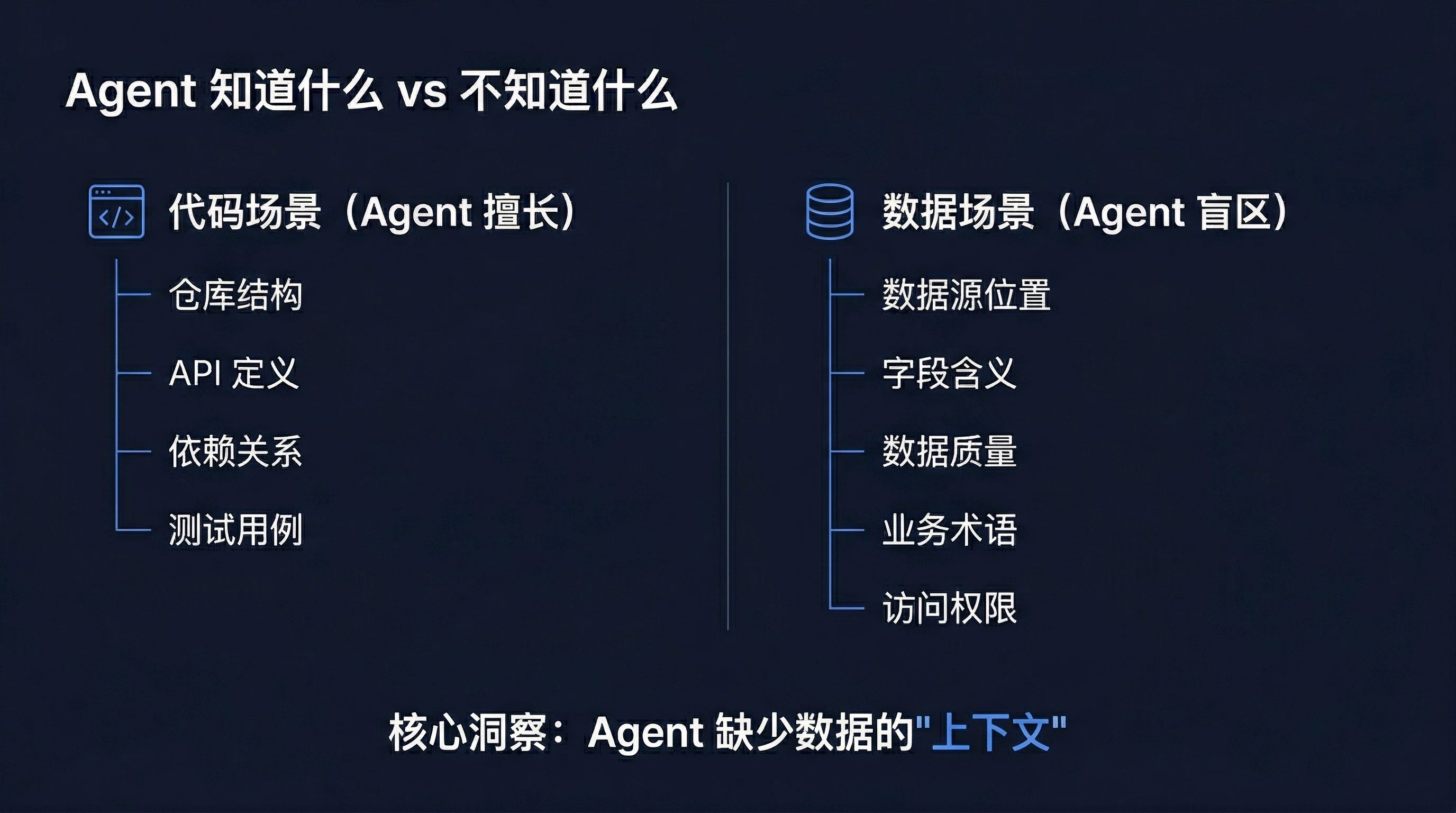
这就是问题的根源。通用 AI Agent 缺少企业数据的"地图"。
不仅仅是"不知道数据在哪"这么简单。一个真正能处理数据问题的 Agent,需要理解以下四个维度:

1. 数据源拓扑——企业的数据分布在哪些系统?MySQL 存订单、PostgreSQL 存用户行为、Excel 存手工报表、飞书多维表格存项目进度……这些系统之间有什么关联?
2. 元数据质量——字段名叫 status,它的值有哪些?是 0/1/2 还是 pending/approved/rejected?字段 amount 的单位是元还是万元?没有这些上下文,AI 生成的 SQL 几乎必然是错的。
3. 权限边界——谁能看什么数据?行级过滤规则是什么?跨数据源查询时需要遵循什么合规要求?
4. 业务语义——"活跃用户"的定义是什么?"高价值订单"的阈值是多少?"华东"包括哪些省份?这些业务知识不在任何数据库的 schema 里。
缺少这四张"地图"的 AI Agent,就像没有 GPS 的司机——知道怎么开车,但不知道去哪里、走哪条路、哪些路段限行。
面对这个问题,业界常见的做法是:
这些方案都在"修补",而不是"解决"。我们需要的是一个专门为 AI Agent 设计的数据基础设施。
让我们看一个真实场景。某互联网公司的技术团队在引入 Claude Code 后,尝试让它回答业务数据问题。

第一轮尝试:直接把数据库 schema 塞进 prompt。
你是一位数据分析师。以下是我们的数据库结构:
-- orders 表:id, user_id, amount, status, created_at...
-- users 表:id, name, region_code, level...
-- products 表:id, name, category, price...
结果:Agent 生成的 SQL 经常出错。因为它不知道 status = 3 代表什么,也不知道 region_code = '310000' 是上海。
第二轮尝试:在 prompt 里加上字段说明。
-- orders.status: 0=待支付, 1=已支付, 2=已发货, 3=已完成, 4=已取消
-- users.region_code: 行政区划代码,310000=上海...
结果:好了一些,但 prompt 变得越来越长。当公司有 20 个数据库、200 张表时,schema 描述加上字段说明轻松突破 10 万字——远超任何模型的上下文窗口。
第三轮尝试:用 RAG 检索相关 schema。
结果:检索出来的 schema 片段经常不完整。用户问"华东区销售额",RAG 找到了 orders 表的 schema,但没有找到 region_code 的定义(因为定义在另一个文档里)。
最终结果:团队放弃了让 Agent 直接查数据的想法,回归到"人工写 SQL + Agent 辅助优化"的老路。
这个案例不是个例。它揭示了一个根本性的问题:现有的工具和方法论,不是为"AI Agent 理解企业数据"这个场景设计的。
我们需要一个从底层重新思考的解决方案。
在回答"AskTable 能做什么"之前,先回答一个更基础的问题:为什么像 Claude Code 和 OpenClaw 这样强大的 AI Agent,还需要专门的数据管理工具?
Claude Code 是 Anthropic 推出的 AI 编程助手,它的核心能力体现在:
这些能力让 Claude Code 成为开发者的"副驾驶"。但它的能力有一个前提:它需要完整的上下文信息。
在代码场景中,上下文是天生的——文件、目录、import 关系、API 定义,都是结构化的、可遍历的。
在数据场景中,上下文是缺失的——数据库连接信息不在代码库里,字段含义不在注释里,权限规则不在文档里。
Claude Code 擅长的是"已知上下文的推理",而不是"未知上下文的探索"。
OpenClaw 作为 2026 年 GitHub 上增长最快的开源 AI 助手,拥有 6000+ 插件和技能的生态系统。它的优势在于:
但同样,OpenClaw 的技能生态集中在代码开发、文件操作、API 调用等领域。在数据管理方面,它缺少:
OpenClaw 擅长的是"调用工具",但数据管理需要的不只是工具调用,还需要领域知识和治理能力。
这就是 AskTable 的定位差异。
传统的数据库管理工具(如 Navicat、DBeaver)是给人用的 GUI 工具——它们假设用户理解 SQL、理解 schema、理解权限模型。
AskTable 是给 Agent 用的数据基础设施——它假设使用者是一个需要完整上下文信息的 AI,而不是一个有数据库经验的人类。
这种定位差异,决定了 AskTable 在架构设计上与传统工具的根本不同:
| 维度 | 传统数据库工具 | AskTable |
|---|---|---|
| 目标用户 | 数据工程师/DBA | AI Agent |
| 信息呈现 | Schema 浏览器 | 语义化知识图谱 |
| 操作方式 | GUI 点击/SQL | CLI + Skill |
| 权限模型 | 数据库原生 RBAC | 业务语义级策略 |
| 优化方式 | 手动索引/调优 | AI 自动建议 |
AskTable 的定位不是"又一个数据分析工具",而是AI Agent 的数据基础设施层。它解决的不是"如何查数据"的问题,而是"如何让 AI Agent 理解和治理企业数据"的问题。
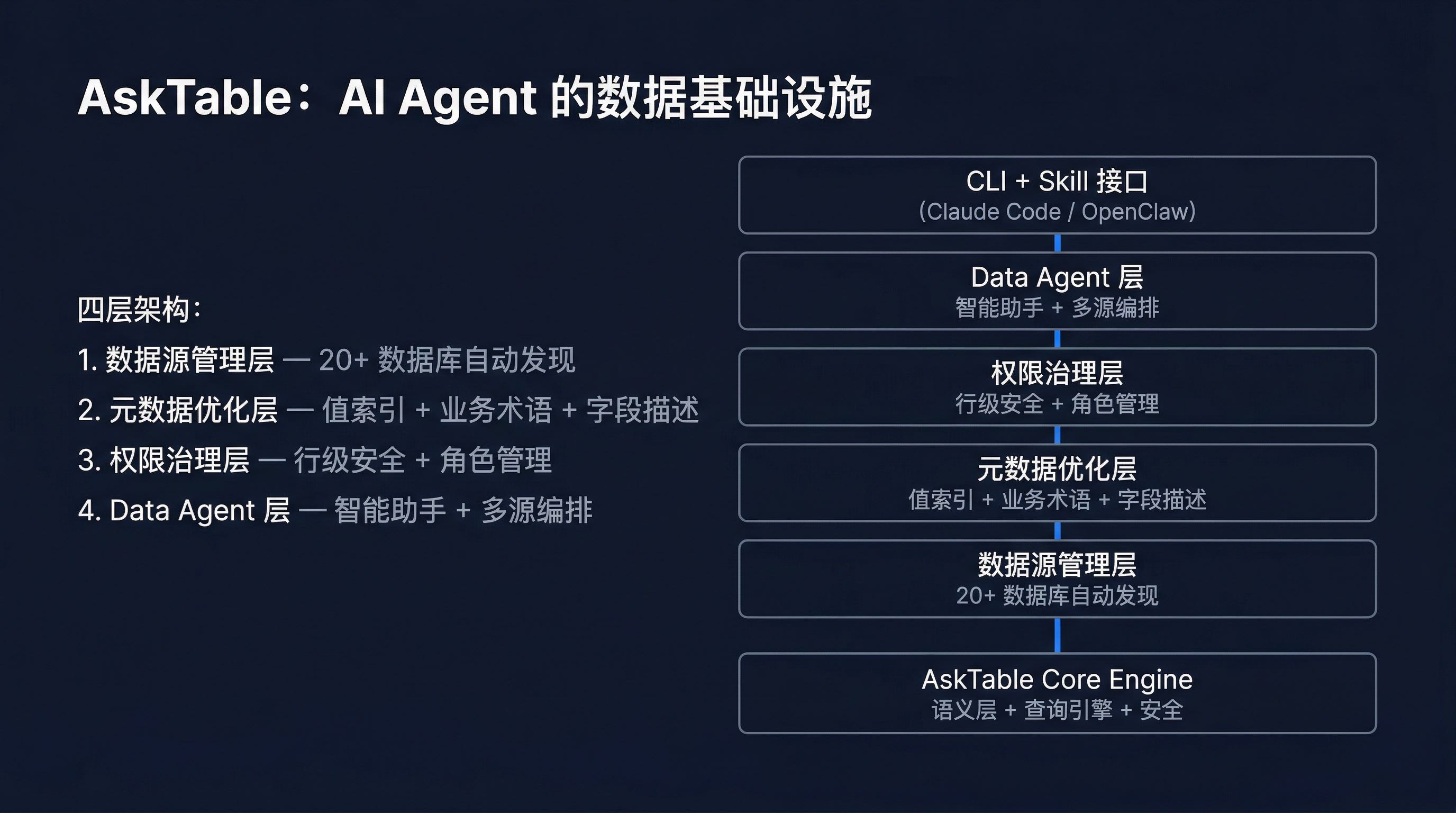
AskTable 支持 20+ 种数据库和数据源的接入,覆盖企业最常见的数据存储形态:
每一种数据源,AskTable 都提供了完整的适配器,包括连接池管理、元数据发现、方言适配等功能。
AI Agent 通过 AskTable CLI 可以实现完整的数据源生命周期管理:
# 创建数据源
$ asktable ds create --name "订单数据库" --engine mysql \
--config '{"host":"...","database":"orders","user":"readonly"}'
✓ 数据源创建成功 (ID: ds_mysql_001)
# 列出所有数据源及其状态
$ asktable ds list
ID 名称 引擎 表数 状态
ds_mysql_001 订单数据库 MySQL 15 ✓ 已连接
ds_pg_001 用户行为 Postgres 8 ✓ 已连接
ds_excel_001 销售报表 Excel 1 ✓ 已上传
ds_excel_002 员工信息 Excel 1 ✓ 已上传
ds_excel_003 产品目录 Excel 1 ✓ 已上传
# 查看数据源详情
$ asktable ds status ds_mysql_001
名称:订单数据库
引擎:MySQL 8.0
连接状态:✓ 正常
表数量:15
字段总数:127
最后同步:2026-04-04 10:30:00
元数据质量评分:85/100
关键价值:Agent 不再需要"猜"数据在哪。AskTable 为 Agent 维护了一份完整的数据源目录,包括连接状态、表数量、最近同步时间、元数据质量评分等信息。这相当于给 Agent 提供了一张"企业数据地图"。
这是 AskTable 最核心的差异化能力。仅仅知道"有哪些表"是不够的,Agent 需要理解"这些表意味着什么"。
AskTable 提供三层元数据优化机制:

值索引(Value Index)——为关键字段建立值域索引,解决 Agent 写 WHERE 条件时"猜值"的问题:
# 为 status 字段创建值索引
$ asktable ds index create ds_mysql_001 \
--schema orders --table orders --field status
# 查看索引结果
$ asktable ds index list ds_mysql_001
Schema Table Field 值域
orders orders status [pending, confirmed, shipped, delivered, cancelled]
orders orders customer_id [C001, C002, ..., C1247] (1247 个唯一值)
orders orders product_id [P0001, P0002, ..., P0892] (892 个唯一值)
当 Agent 需要写 WHERE status = ? 时,它不再需要猜测合法值是什么,而是直接从索引中获取。这直接消除了 Text-to-SQL 场景中约 40% 的常见错误(错误的枚举值)。
业务术语表(Business Glossary)——建立业务语言与数据字段的映射,解决"业务说的和数据库说的不一样"的问题:
$ asktable glossary create \
--term "活跃用户" \
--definition "近30天内有登录行为的用户" \
--related-tables users,login_logs
$ asktable glossary create \
--term "高价值订单" \
--definition "订单金额超过10000元的订单" \
--related-tables orders
$ asktable glossary create \
--term "华东" \
--definition "包括上海、江苏、浙江、安徽、福建、江西、山东"
当用户问"华东区的销售额"时,Agent 能自动将"华东"映射到正确的地理过滤条件:
WHERE province IN ('上海', '江苏', '浙江', '安徽', '福建', '江西', '山东')
字段描述优化——AI 自动为字段生成业务级别的描述,将技术语言翻译为业务语言:
$ asktable ds meta optimize ds_mysql_001
# AI 自动分析字段名、样例值、关联关系、外键约束
# 生成可读的字段描述
# 优化前:status INT(11) COMMENT '订单状态'
# 优化后:status INT(11) - 订单生命周期状态
# 0=pending(待支付,刚下单未付款)
# 1=confirmed(已支付,付款成功等待发货)
# 2=shipped(已发货,物流进行中)
# 3=delivered(已签收,订单完成)
# 4=cancelled(已取消,用户主动取消或超时未支付)
效果对比:
| 优化前 | 优化后 |
|---|---|
Agent 看到 status INT(11) | Agent 知道 status 的值域和业务含义 |
Agent 看到 region_code VARCHAR(10) | Agent 知道 "华东" 包含哪些省份 |
| Agent 猜测字段关系 | Agent 理解 customer_id 关联 users 表 |
| 用户说"活跃用户",Agent 不知道 | Agent 自动关联 users 和 login_logs |
根据实际测试,经过元数据优化后,SQL 生成准确率提升 30%+,响应速度提升 3-5 倍。这是因为 Agent 不再需要"试错",而是基于完整的知识一次生成正确的 SQL。
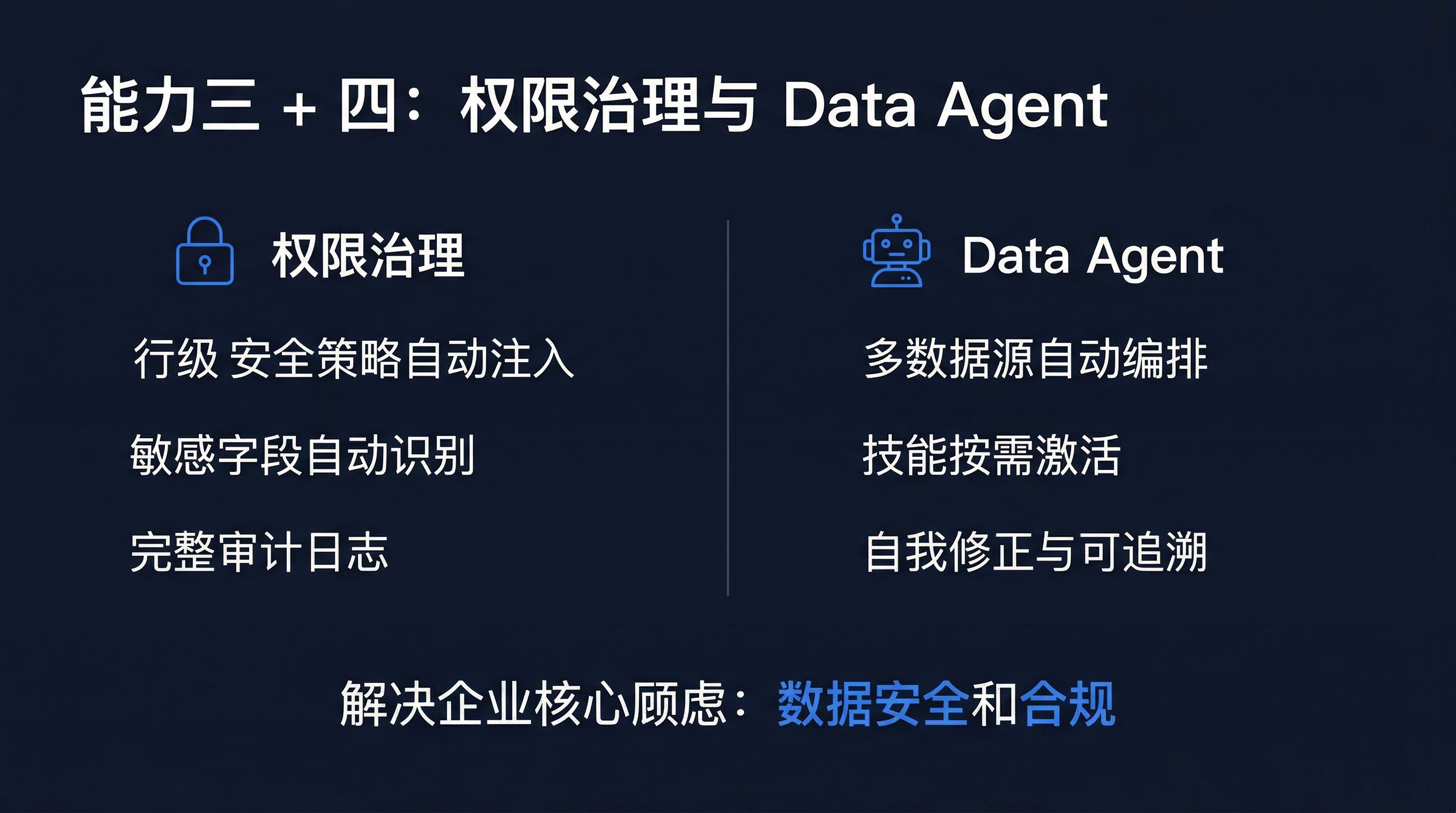
企业数据管理中最敏感的环节是权限。AskTable 提供完整的权限治理能力:
# 创建行级安全策略
$ asktable policy create \
--name "员工自查策略" \
--permission allow \
--datasources ds_mysql_001,ds_pg_001 \
--rows-filter '{"*.*.employee_id": "{{employee_id}}"}'
# 创建角色
$ asktable role create --name "普通员工" --policies policy_employee
$ asktable role create --name "管理层" --policies policy_manager
AI Agent 通过 AskTable 可以:
这解决了企业使用 AI Agent 时的核心顾虑:数据安全和合规。
AskTable 的 Data Agent 是一个专门的数据分析智能体,它是 AskTable 数据基础设施的"消费端":
Data Agent 的核心价值在于:它不是简单地执行 SQL,而是像一个有经验的数据分析师一样思考。
用户问题:"为什么上个月华东区的销售额下降了?"
Data Agent 思考过程:
1. 理解问题:华东区、上个月、销售额、下降
2. 数据发现:找到 orders 表,关联 region 映射
3. 初步查询:获取华东区本月 vs 上月销售额
4. 确认下降:确实下降了 15%
5. 根因分析:
a. 按产品线拆分 → 发现 A 产品线下降 40%
b. 按渠道拆分 → 发现线上渠道正常,线下渠道下降 55%
c. 按时间拆分 → 发现第二周开始明显下滑
6. 关联分析:查询天气数据 → 华东区第二周有台风
7. 结论生成:台风天气导致线下门店客流下降,是销售下滑的主因
这种分析能力,来自 AskTable 底层完整的元数据支持和 Data Agent 的多步骤推理能力。
理论再好,不如一个真实的案例有说服力。让我们深入看一个企业每天都会遇到的场景。

公司:一家年 GMV 约 5000 万的中型电商企业 数据团队:2 名数据工程师 + 1 名数据分析师 数据分布:
需求:
如果通过 AskTable 网页端手动操作,需要完成以下步骤:
| 步骤 | 操作 | 预估耗时 |
|---|---|---|
| 1 | 逐个创建 5 个数据源(填写连接参数、测试连接) | 10 分钟 |
| 2 | 等待 5 次元数据同步 | 5 分钟 |
| 3 | 逐个手动创建值索引(每个数据源约 5 个字段) | 20 分钟 |
| 4 | 逐个手动添加业务术语(约 10 个术语) | 15 分钟 |
| 5 | 创建 Data Agent 并关联所有数据源 | 5 分钟 |
| 6 | 创建行级安全策略(逐条配置过滤规则) | 15 分钟 |
| 7 | 创建角色并关联策略 | 5 分钟 |
| 8 | 测试权限是否生效(用不同角色试查) | 10 分钟 |
| 9 | 手动优化字段描述(127 + 64 + 30 = 221 个字段) | 30-45 分钟 |
预计总耗时:1.5-2 小时
隐含成本:
同样的场景,通过 Claude Code 或 OpenClaw 的 AskTable Skill,只需要一句指令:
你:帮我配置以下数据源,并创建一个统一的查询 Bot:
1. MySQL 数据库(订单数据)
- Host: db.company.com
- Database: orders
- User: readonly
2. PostgreSQL 数据库(用户行为)
- Host: analytics.company.com
- Database: user_events
3. 三个 Excel 文件:
- sales_2024.xlsx(销售报表)
- employees.xlsx(员工信息)
- products.xlsx(产品目录)
权限要求:
- 普通员工只能看自己的数据(通过 employee_id 过滤)
- 管理层可以看全部数据
完成后帮我优化一下元数据,该加索引的加索引,该加术语的加术语。
接下来,Agent 自动执行完整的配置流程。以下是完整的执行过程:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第一步:创建数据源
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[1/5] MySQL 订单数据
$ asktable ds create --name "订单数据" --engine mysql \
--config '{"host":"db.company.com","database":"orders","user":"readonly","password":"***"}'
✓ 数据源创建成功 (ID: ds_mysql_001)
- 检测到 15 张表, 127 个字段
- 已验证连接权限为只读
[2/5] PostgreSQL 用户行为
$ asktable ds create --name "用户行为数据" --engine postgres \
--config '{"host":"analytics.company.com","database":"user_events","user":"readonly","password":"***"}'
✓ 数据源创建成功 (ID: ds_pg_001)
- 检测到 8 张表, 64 个字段
[3/5] Excel - 销售报表
$ asktable ds create --name "销售报表" --engine excel
✓ 数据源创建成功 (ID: ds_excel_001)
$ asktable ds upload ds_excel_001 sales_2024.xlsx
✓ 文件上传完成 (3.2 MB, 12 个字段)
[4/5] Excel - 员工信息
$ asktable ds create --name "员工信息" --engine excel
✓ 数据源创建成功 (ID: ds_excel_002)
$ asktable ds upload ds_excel_002 employees.xlsx
✓ 文件上传完成 (1.1 MB, 8 个字段)
[5/5] Excel - 产品目录
$ asktable ds create --name "产品目录" --engine excel
✓ 数据源创建成功 (ID: ds_excel_003)
$ asktable ds upload ds_excel_003 products.xlsx
✓ 文件上传完成 (0.8 MB, 10 个字段)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第二步:同步元数据
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
$ asktable ds meta sync ds_mysql_001 --wait
✓ MySQL 元数据同步完成 (15 张表, 127 个字段)
$ asktable ds meta sync ds_pg_001 --wait
✓ PostgreSQL 元数据同步完成 (8 张表, 64 个字段)
$ asktable ds meta sync ds_excel_001 --wait
✓ 销售报表元数据同步完成 (1 张表, 12 个字段)
$ asktable ds meta sync ds_excel_002 --wait
✓ 员工信息元数据同步完成 (1 张表, 8 个字段)
$ asktable ds meta sync ds_excel_003 --wait
✓ 产品目录元数据同步完成 (1 张表, 10 个字段)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第三步:智能优化元数据
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
分析关键字段,创建值索引...
$ asktable ds index create ds_mysql_001 \
--schema orders --table orders --field customer_id
$ asktable ds index create ds_mysql_001 \
--schema orders --table orders --field product_id
$ asktable ds index create ds_mysql_001 \
--schema orders --table orders --field status
$ asktable ds index create ds_pg_001 \
--schema public --table events --field user_id
$ asktable ds index create ds_excel_002 \
--schema public --table employees --field employee_id
$ asktable ds index create ds_excel_003 \
--schema public --table products --field product_name
✓ 已为 6 个关键字段创建值索引
- customer_id: 1,247 个唯一值
- product_id: 892 个唯一值
- status: [pending, confirmed, shipped, delivered, cancelled]
- user_id: 8,432 个唯一值
- employee_id: 156 个唯一值
- product_name: 892 个唯一值
添加业务术语...
$ asktable glossary create --term "活跃用户" \
--definition "近30天内有登录行为的用户"
$ asktable glossary create --term "高价值订单" \
--definition "订单金额超过10000元的订单"
$ asktable glossary create --term "华东" \
--definition "包括上海、江苏、浙江、安徽、福建、江西、山东"
✓ 已添加 3 个业务术语
优化字段描述...
$ asktable ds meta optimize ds_mysql_001
$ asktable ds meta optimize ds_pg_001
✓ AI 已为 191 个字段生成业务描述
- MySQL: 127 个字段
- PostgreSQL: 64 个字段
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第四步:创建统一 Bot
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
$ asktable bot create --name "企业数据助手" \
--datasources ds_mysql_001,ds_pg_001,ds_excel_001,ds_excel_002,ds_excel_003
✓ Bot 创建成功 (ID: bot_unified_001)
- 关联 5 个数据源
- 支持跨数据源查询
- 已启用元数据优化
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
第五步:配置权限
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[创建策略 - 员工自查]
$ asktable policy create \
--name "员工自查策略" \
--permission allow \
--datasources ds_mysql_001,ds_pg_001,ds_excel_001,ds_excel_002,ds_excel_003 \
--rows-filter '{"*.*.employee_id": "{{employee_id}}"}'
✓ 策略创建成功 (ID: policy_employee)
[创建策略 - 管理层全览]
$ asktable policy create \
--name "管理层全览策略" \
--permission allow \
--datasources ds_mysql_001,ds_pg_001,ds_excel_001,ds_excel_002,ds_excel_003
✓ 策略创建成功 (ID: policy_manager)
[创建角色]
$ asktable role create --name "普通员工" --policies policy_employee
✓ 角色创建成功 (ID: role_employee)
$ asktable role create --name "管理层" --policies policy_manager
✓ 角色创建成功 (ID: role_manager)
[权限验证]
$ asktable policy test policy_employee \
--variables employee_id=E001
✓ 策略验证通过 - 员工 E001 只能看到自己的数据
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
完成!配置总结
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
✓ 5 个数据源已配置并优化
- MySQL: 15 张表, 127 个字段
- PostgreSQL: 8 张表, 64 个字段
- Excel: 3 个文件, 30 个字段
✓ 元数据已优化
- 6 个值索引已创建
- 3 个业务术语已添加
- 191 个字段描述已生成
✓ 1 个统一查询 Bot
- 支持跨数据源查询
- 自动关联相关数据
✓ 2 个角色 + 2 个权限策略
- 普通员工:只能查询自己的数据
- 管理层:可以查询全部数据
- 权限验证已通过
现在你可以这样使用:
[普通员工查询]
$ asktable query bot_unified_001 "我上个月的销售额" \
-r role_employee -V employee_id=E001
→ 只返回 E001 员工的数据
[管理层查询]
$ asktable query bot_unified_001 "上个月全公司的销售额" \
-r role_manager
→ 返回全部数据
[跨数据源查询]
$ asktable query bot_unified_001 "销售额最高的 10 个产品的详细信息"
→ 自动关联订单数据(MySQL)和产品目录(Excel)
总耗时:约 3 分钟
| 维度 | 手动操作 | Agent + AskTable | 提升倍数 |
|---|---|---|---|
| 耗时 | 1.5-2 小时 | 3 分钟 | 30-40x |
| 操作步骤 | 30+ 步 | 1 条指令 | - |
| 出错概率 | 高(容易遗漏配置) | 低(Agent 自动检查) | - |
| 元数据质量 | 依赖个人经验 | 自动优化,标准化 | 质量一致 |
| 可重复性 | 每次都要重新来 | 脚本化,可复用 | - |
| 权限安全 | 容易配置遗漏 | Agent 自动验证 | 更安全 |
| 字段描述 | 手工编写 221 个字段 | AI 自动生成 191 个字段 | 效率 40x+ |
40 倍的效率提升,不是魔法,而是正确的工具组合。
上面展示的是效率的提升。但 AskTable 与 AI Agent 结合的真正价值,远不止于此。

传统的数据管理是一个高度专业化的领域,有着明确的分工和壁垒:
┌───────────────────────────────────────────────┐
│ 传统数据管理组织架构 │
├───────────────────────────────────────────────┤
│ │
│ 数据工程师 ── 数据仓库建模、ETL 管道、数据质量 │
│ ↓ │
│ DBA ────── 数据库运维、权限管理、性能调优 │
│ ↓ │
│ 数据治理 ── 元数据标准、术语规范、合规审计 │
│ ↓ │
│ 业务分析师 ── 通过 BI 工具"消费"数据 │
│ │
│ 壁垒:每层之间都有明显的知识和技能鸿沟 │
└───────────────────────────────────────────────┘
AskTable + AI Agent 的组合正在打破这些角色之间的壁垒:
这不是"替代"数据工程师,而是让他们专注于更高价值的工作。数据工程师定义数据模型和质量规则,Agent 负责执行和优化。
在传统的 DevOps 实践中,"左移"意味着将安全和质量检查提前到开发阶段。在数据领域,我们提出数据治理左移的概念:
过去:事后治理
数据接入 → 使用数据 → 发现问题 → 修复数据 → 配置权限 → 审计
↑ |
└────────── 通常在问题暴露后才发现 ─────┘
现在:事前预防
数据接入 → AskTable 自动发现 → 元数据优化 → 权限建议 → 持续监控
↓
在数据可用的同时,
治理也已完成
这意味着:
AskTable 的 Skill 系统 让这种优化不是一次性的,而是持续的、自进化的:
数据接入 → 自动发现 → 元数据优化 → 查询反馈 → 持续调优
↑ |
└──────────────────────────────────────────────────────┘
持续优化闭环
具体来说:
数据基础设施不再是一个"配置完就放着"的静态系统,而是一个会自我优化的动态系统。
当 AI Agent 拥有了数据管理能力,企业的工作模式会发生根本性变化。
过去的工作流(1-4 周):
业务需求 → 提交数据需求单 → 等待排期 → 数据工程师建模 →
DBA 授权 → BI 开发报表 → 业务人员查看 → 发现问题 →
重新提交需求 → 等待下一轮排期 → ...
典型周期:1-4 周
典型沟通成本:5-10 次跨部门会议
新的工作流(3 分钟 - 1 小时):
业务需求 → 告诉 Agent → Agent 自动完成:
1. 检查并接入所需数据源
2. 优化相关元数据
3. 配置访问权限
4. 生成查询结果或报表
→ 即时查看 → 发现问题 → 直接告诉 Agent 调整
典型周期:3 分钟 - 1 小时
典型沟通成本:0(人与 Agent 对话即可)
这不是"工具升级",而是思维方式的改变。数据不再是少数人的专属领域,而是每个 Agent 都能理解和操作的基础设施。
在传统的 AI 数据分析场景中,安全性是一个持续的挑战:
AskTable 从架构层面解决这些问题:
站在这个时间点,我们看到的不仅仅是一个工具的诞生,而是一个新范式的起点。

未来 12-18 个月,我们会看到以下趋势:
趋势一:Agent 原生数据管理
就像现在的编程 Agent 天然理解代码仓库一样,未来的通用 Agent 将天然理解企业的数据资产。不需要额外配置,Agent 一"入职"就知道:
这种"数据感知"能力,将成为 AI Agent 的标准配置,就像现在的"代码感知"一样自然。
趋势二:数据治理的自动化
数据质量监控、元数据更新、权限审计这些传统上需要人工完成的工作,将完全由 Agent 自动完成:
趋势三:跨组织的数据协作
当每个组织都有自己的数据 Agent 时,组织间的数据协作将变成 Agent 之间的对话:
趋势四:从"数据分析"到"数据决策"
当 Agent 不仅能查数据,还能管数据时,数据分析的终点不再是"看到数据",而是"做出决策":
AskTable 正在沿着这个方向持续投入,以下是我们正在推进的方向:
如果你是一个项目负责人,正在考虑如何将 AI Agent 引入企业的数据工作流,以下是我们的建议:
第一步:从数据源接入开始(第 1 周)
不要一上来就追求"全自动"。先把企业的数据资产用 AskTable 管理起来:
第二步:让 Agent 帮忙优化(第 2 周)
利用 Claude Code 或 OpenClaw 的 AskTable Skill,让 Agent 自动完成:
第三步:逐步扩展 Agent 的数据能力(持续)
随着 Skill 系统的成熟,让 Agent 承担更复杂的数据治理任务:
AI Agent 已经足够强大,能够理解代码、规划任务、执行复杂的工作流。但在企业数据面前,它们依然"睁眼瞎"——不是因为不够聪明,而是因为缺少一张"地图"。
AskTable 就是这张地图。
它不是一个替代 AI Agent 的工具,而是让 AI Agent 真正具备数据管理能力的基础设施。通过数据源管理、元数据优化、权限治理和 Data Agent 四大能力,AskTable 让通用 AI Agent 从"能写代码"进化到"能管数据"。
从"问数据"到"管数据"——这不是一个简单的功能升级,而是企业数据工作方式的范式转移。
当每个 AI Agent 都拥有数据管理能力时,数据不再是企业的"暗物质"——看不见、摸不着、猜不透。它变成了 Agent 可以轻松理解和操作的基础设施,就像代码仓库一样透明、一样可控。
这个未来,比我们想象的来得更快。

了解更多:
