
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家

最近跟几个做数据的朋友聊天,绕不开一个话题。
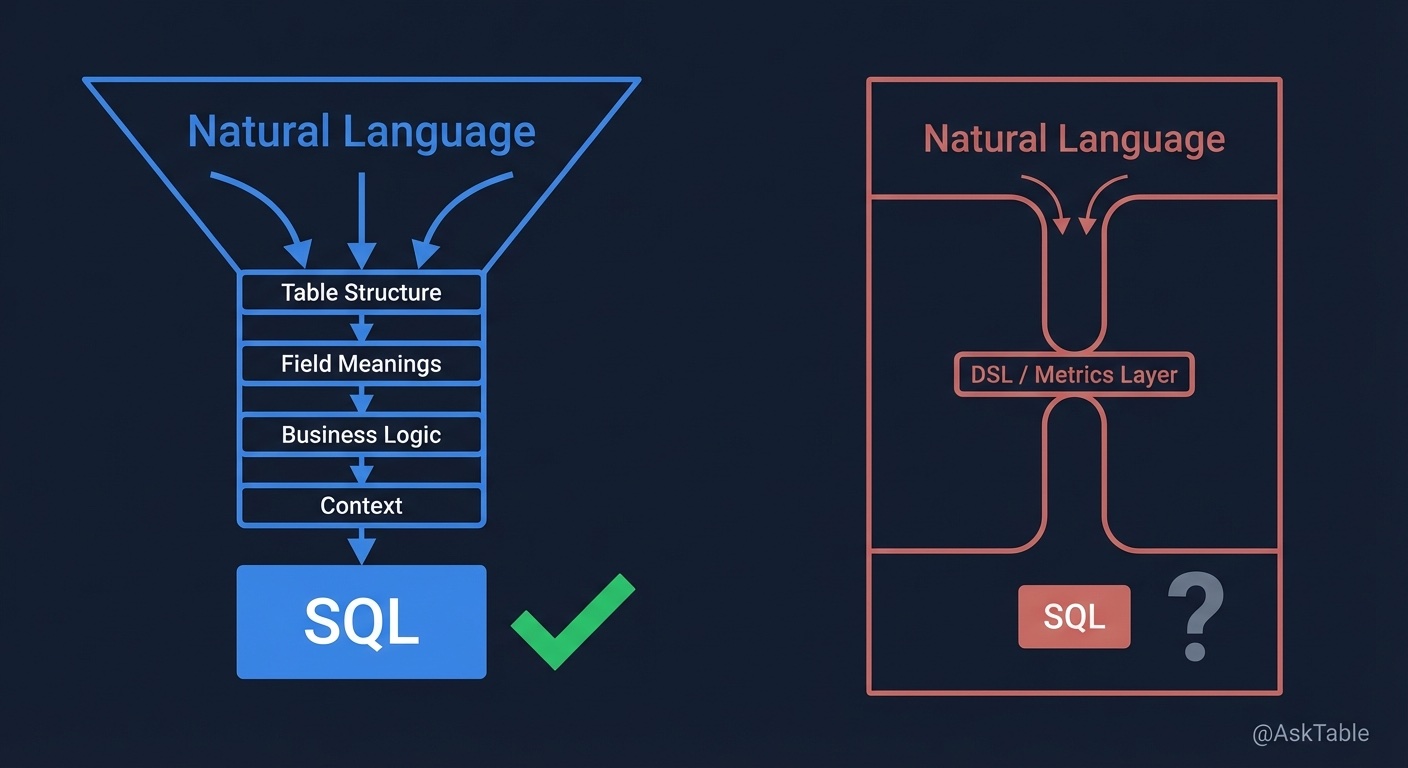
到底让不让大模型直接写 SQL。
一方说,直接让大模型生成 SQL 就行,别整那些花里胡哨的。另一方说,不行,必须有中间层,先让大模型生成语义层或者指标层或者 DSL,再由中间层转成 SQL。两边都挺坚持,聊得也挺投入。
我当时觉得挺有意思的。但越听越觉得,大家好像吵错架了。
技术之争,永远是最安静的浪费。没有输赢,问题还在那儿。
天下苦数据久矣。
所有人都知道数据重要。老板开会说数据驱动,汇报写数据赋能,融资讲数据壁垒。但真到了要干活的时候呢,没人愿意碰。
太脏了。活太脏,不想干。
我跟你说个画面,你可能有感觉。一个数据工程师,早上九点半坐下,打开编辑器,面对的是六十多个表,每个表平均四十多个字段,其中三分之一的字段注释是空的,剩下三分之二的注释是三年前的同事写的,描述叫「备用字段1」「备用字段2」「temp_field」。他今天要写的,是一个运营同事用自然语言描述的需求,「帮我看一下上个季度华东地区复购率的变化趋势」。
他需要自己去找哪些表有地区信息,哪些表有订单数据,哪些表有用户行为,这些表之间的关联关系是什么,有没有历史变更,字段命名是不是一致的。
然后开始写 JOIN。
一个又一个 JOIN。
这不是技术能力的问题。这是一个工作了一年的工程师,只要理解了需求和数据,就能干好的事。但问题是,他不想干了。他每天干这个,干到觉得人生没什么意思。
这不是他一个人的问题。是整个行业的问题。
说到这个,就回到开头那个争论。中间层,到底能不能解决这个问题?
我们自己做 AskTable 的时候,也反复想这个问题。中间层不是没有用,它有用。但你想过没有,中间层谁来维护,谁定义,怎么管理,怎么更新,怎么扩展。
让业务干吗。不可能。业务连数据字典都没看过。
让技术干吗。繁琐。都 2026 年了,还要让人去手动维护一套语义层,去定义每一个指标的计算口径,去管理每一次业务变更带来的更新。你想想看,这不就是给一个已经不想上班的人说,你先花两周把你的工位重新装修一下,再开始干活吗。
那如果不搞中间层呢,直接让大模型上 SQL。准吗?
这个问题问得对。但回答之前,得先拆开看。因为这里其实是两个问题,不是一个。
第一个问题,大模型的能力,能不能根据自然语言写出准确的 SQL。
你换个问法就知道了。一个工作了一年的人,熟悉你现在的业务和表,他能不能根据需求写出准确的 SQL。能。他只要理解了需求,理解了数据,他就能干这个事。这个基本上没有什么悬念。
那大模型呢。在这个技术技能上,一定比人强。
它不会忘记 JOIN 的条件,不会拼错字段名,不会在凌晨三点把 SUM 写成 AVG。它读过比你见过的更多的 SQL 语料,理解比你写过更多的模式。它在这个具体的技能点上,碾压一个普通工程师。这一点,我觉得没什么好争的。
那问题出在哪。
第二个问题。你让大模型直接生成 SQL,你到底有没有给到它完整的 context。
这才是核心。
如果你没有给到,你谈什么准不准,没有意义。就像你让一个工程师闭着眼睛写 SQL,然后说他写的不准。这公平吗。不公平。
我跟你说,这里其实是两种完全不同的态度。
一种是我相信大模型,所以我给到它完整的,清晰的,准确的 context。我把表结构、字段含义、业务逻辑、历史口径、关联关系,全部给它。我不藏,我不留,我不觉得它会搞砸。
另一种是我不相信它,所以我给它限定一个框。你只能用这几个指标,你只能按这个模板来,你只能生成 DSL 不能直接生成 SQL。你在这个范围里干活,别越界。
后者能干嘛。能提效。确实。
而且在一些固定查询模式特别多的场景下,中间层这条路也有它不可替代的价值。查询模式不发散,不需要创造力,就是日复一日同样的指标口径反复查。这个时候 DSL 的速度优势就出来了,而且稳定,不会出幺蛾子。
坦率的讲,这不是一个非此即彼的游戏。没有哪条路是绝对正确的。选哪条,取决于你是什么团队,你的查询模式是什么,你的业务需不需要那些「意料之外」的惊喜。
但也就这样了。
没有惊喜。没有 aha moment。没有那些让你觉得「卧槽,这也能行」的瞬间。新的能力和价值点,是没有的。它只能干以前你干的,只是干得快了一点。
这才是最大的浪费。不是算力,是想象力。
你自己的想象力,被你设的那个框,控制住了。
我有时候觉得,这件事特别像工业革命初期的一幕。那时候有了内燃机,有了汽车。但很多人不放心,给汽车装上了马的缰绳和马鞭的支架。他们管这东西叫 horseless carriage,没有马的马车。
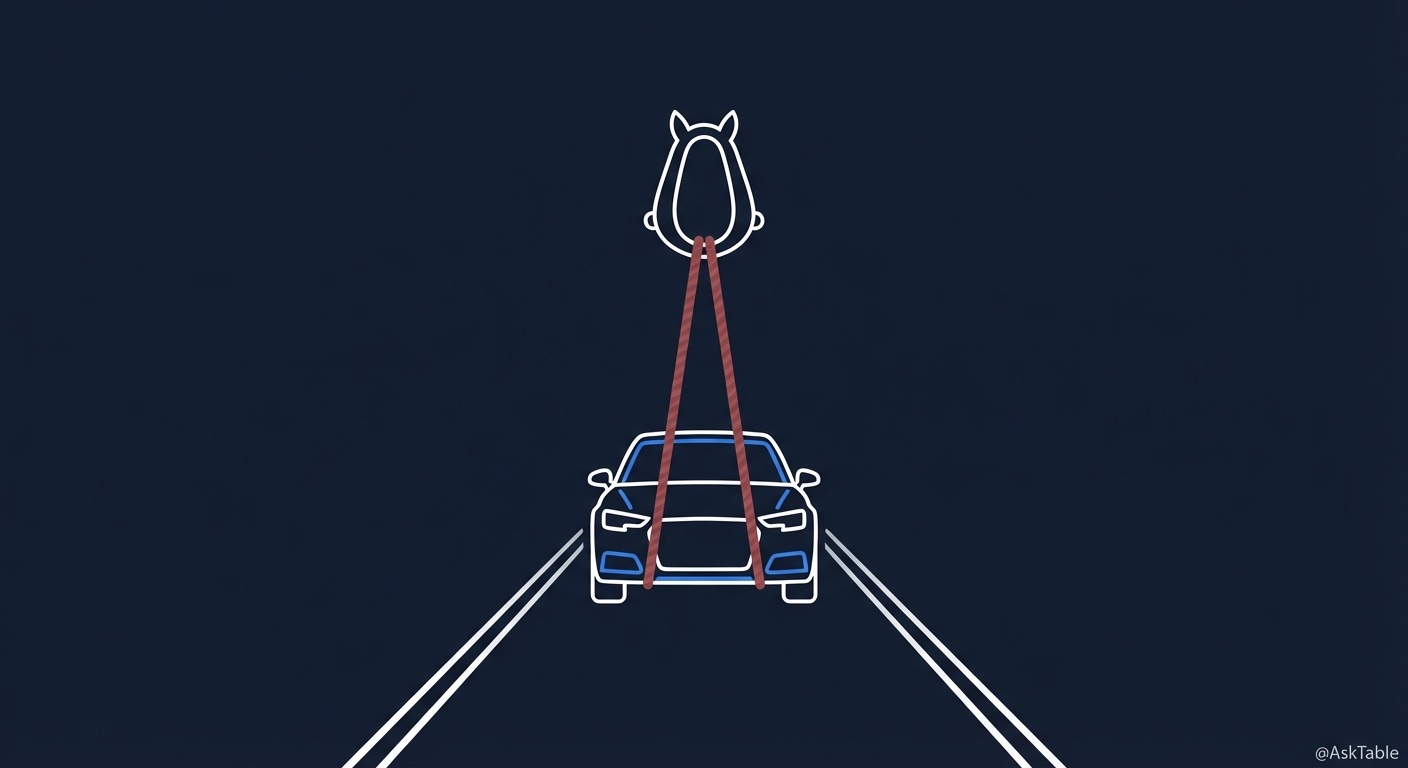
你能理解他们。新技术来了,怕失控,怕出问题,所以要套上熟悉的框架。但你想过没有,汽车的上限,被缰绳控制住了。它的速度,它的灵活性,它的可能性,全被那个框给限死了。
我们现在干的事,一模一样。
我们总担心大模型失控。怕它写出错的 SQL,怕它理解错了口径,怕它幻觉。所以我们加框,加语义层,加指标管理,加校验层。每一层都是出于善意,都是出于谨慎。但加着加着,大模型能做的事,就只剩下了「在框里提效」。
不是说这些框架完全没有价值。在某些场景下,在某些对准确率要求极高的固化场景,在某些合规极其严格的行业,这些框是必要的。我承认。
但如果你做的不是这些场景呢。如果你只是一般的业务分析,一般的运营查询,一般的数据探索呢。你还要加三层框吗。
我自己也还在摸索。说实话我们做 AskTable 的时候,也踩过这个坑。后来想明白了,这不是技术问题,这是信任问题。
你敢不敢给到它完整的 context。
你给到了,它大概率会给你一个惊喜。你给不到,它就会给你一个「还凑合」的答案。然后你说,你看,AI 写 SQL 还是不准。
你相信我,不是它不准。是你没给够。
那 context 怎么给呢。
拿 AskTable 自己来说,我们做了几件事。偏好训练和评测,让模型理解用户习惯。技能体系,记忆机制,风格适配。这些全都是 context。
但坦率地讲,不够。
因为完整的 context 远不止这些。企业的知识库、外部的行业信息、企业决策/行动(本体论概念里的 Action),全在里面。而且这是一件长期的事,今天给到八十,明天发现还差二十。没有捷径,只能持续打磨。
但方向是对的。给到多少,大模型就能给你多少。
这个事我也跟很多团队聊过。他们不争论技术路线,他们就干一件事,把自己的数据上下文整理清楚。表结构,字段注释,业务术语,计算口径,全部标准化。然后丢给大模型。结果是什么,准确率直接飙升。
不需要中间层。不需要 DSL。不需要语义管理。
需要的只是一套完整的,清晰的,准确的数据 context。然后把大模型当做一个真正有能力的人来用,而不是一个需要被严格管控的临时工。
话说回来,技术路线之争为什么没有意义。因为它讨论的是实现路径,而不是问题本身。天下苦数据久矣,苦的是没有人愿意干那些脏活累活,苦的是数据上下文永远是一团乱,苦的是所有人都知道该整理但所有人都在拖延。
你解决了 context 的问题,技术路线的争论自己就消解了。因为你会看到,大模型可以直接写出不错的 SQL,不需要你先花三个月建指标体系。它也可以走中间层的路,取决于你需要什么。
它只需要你信任它,然后把该给的东西给它。
突然想起了一个很久以前的故事。阿波罗登月计划的时候,导航计算机的内存只有 72KB。现在你手机上一个表情包都比它大。但就这台计算机,把人送上了月球。为什么。因为他们没有把精力花在争论「该用什么编程语言更优雅」上,他们把所有能给的上下文,所有能做的准备,全部给到位了。然后计算机干了一件当时所有人觉得不可能的事。
大模型也是一样。它的能力已经远超我们的想象。超纲的不是它,是我们。
是我们还在用管理一个实习生的心态,去管理一个比你见过所有工程师都厉害的工程师。是我们还在用「不能让它出错」的恐惧,去限制一个本来可以给你带来惊喜的伙伴。
这个故事聊到最后,我觉得其实很简单。
你相信它,给到完整的 context,它给你超出预期的结果。你不相信它,加一堆框,它给你一个不出错的平庸答案。然后你觉得 AI 也就这样了。
你觉得 AI 的上限就这样了。
但 AI 的上限从来不是问题。问题是我们的上限。
是我们的想象力,被我们自己框住了。
是我们还在争论该不该让汽车跑过马的速度,而别人已经在造飞机了。
大时代啊,朋友们。
以上,既然看到这里了,如果觉得不错,随手点个赞,在看,转发三连吧,如果想第一时间收到推送,也可以关注我们公众号(AskTable)。
谢谢你看我的文章,我们,下次再见。
