sidebar.joinCommunitysidebar.communicateWithUsers
sidebar.joinAskTableCommunity

sidebar.wechat

sidebar.feishu
sidebar.chooseYourWayToJoin
sidebar.contactUssidebar.getProfessionalSupport

sidebar.aliyunOfferConsultationsidebar.scanForAliyunOffer

sidebar.wechat
sidebar.feishu
sidebar.chooseYourWayToJoin

Recently, I was chatting with some friends who work in data, and one topic kept coming up.
Should we let large language models write SQL directly?
One side says, just let the LLM generate SQL directly, no need for fancy middle layers. The other side says, no way, there must be a middle layer - let the LLM first generate a semantic layer or metric layer or DSL, then convert to SQL through the middle layer. Both sides were quite insistent and engaged in the discussion.
I found it interesting at the time. But the more I listened, the more I felt like everyone was arguing about the wrong thing.
Technical debates are always the quietest waste. There's no winner or loser - the problem remains.
The world has suffered from data for too long.
Everyone knows data is important. Bosses say data-driven in meetings, reports talk about data empowerment, investors discuss data barriers. But when it comes time to actually work? No one wants to touch it.
It's too dirty. The work is too dirty, no one wants to do it.
Let me paint you a picture. A data engineer sits down at 9:30 AM, opens their editor, and faces sixty-plus tables, each with an average of forty-plus fields. One third of the field comments are empty, and the remaining two thirds were written by a colleague three years ago with descriptions like "backup field 1," "backup field 2," "temp_field." What they need to write today is a request from an operations colleague described in natural language: "Help me look at the repurchase rate trend for the East China region last quarter."
They need to figure out which tables have regional information, which tables have order data, which tables have user behavior, what the relationships are between these tables, whether there are historical changes, and whether field naming is consistent.
Then they start writing JOINs.
One JOIN after another.
This isn't a technical capability problem. This is work that any engineer who's been at the job for a year could do, as long as they understand the requirements and the data. But the problem is, they don't want to do it anymore. They do this every day until they feel like life has no meaning.
This isn't just one person's problem. It's the industry's problem.
Speaking of this, we return to the debate at the beginning. Can the middle layer really solve this problem?
When we built AskTable, we thought about this question repeatedly. The middle layer isn't useless - it has its uses. But have you thought about who maintains the middle layer, who defines it, how it's managed, updated, and extended?
Let the business team do it? Impossible. They haven't even read the data dictionary.
Let the tech team do it? Tedious. It's 2026 and we still need people to manually maintain a semantic layer, define calculation criteria for every metric, manage updates from every business change. Think about it - isn't this like telling someone who doesn't want to go to work anymore, "First spend two weeks renovating your workspace, then you can start working"?
So what if we skip the middle layer and let LLMs generate SQL directly? Is it accurate?
That's the right question to ask. But before answering, we need to break it down. Because here are actually two questions, not one.
The first question: can LLMs, based on natural language, write accurate SQL?
Change the wording and you'll see. A person who's been working for a year, familiar with your current business and tables - can they write accurate SQL based on requirements? Yes. As long as they understand the requirements and understand the data, they can do this. This is basically uncontroversial.
So what about LLMs? In this technical skill, they're definitely stronger than humans.
They never forget JOIN conditions, never misspell field names, never write SUM instead of AVG at 3 AM. They've read more SQL than you've ever seen, understand more patterns than you've written. In this specific skill, they crush an average engineer. I don't think there's anything to argue about here.
So where does the problem lie?
The second question. When you let an LLM generate SQL directly, did you give it complete context?
This is the core.
If you didn't give it complete context, talking about accuracy or inaccuracy is meaningless. It's like asking an engineer to write SQL with their eyes closed and then saying they wrote it inaccurately. Is that fair? No.
Let me tell you, there are actually two completely different attitudes here.
One is: I trust the LLM, so I give it complete, clear, accurate context. I give it table structures, field meanings, business logic, historical criteria, relationships - everything. I don't hold back, I don't reserve anything, I don't assume it'll mess up.
The other is: I don't trust it, so I put it in a box. You can only use these metrics, you can only follow this template, you can only generate DSL, not SQL directly. Work within this scope and don't cross the line.
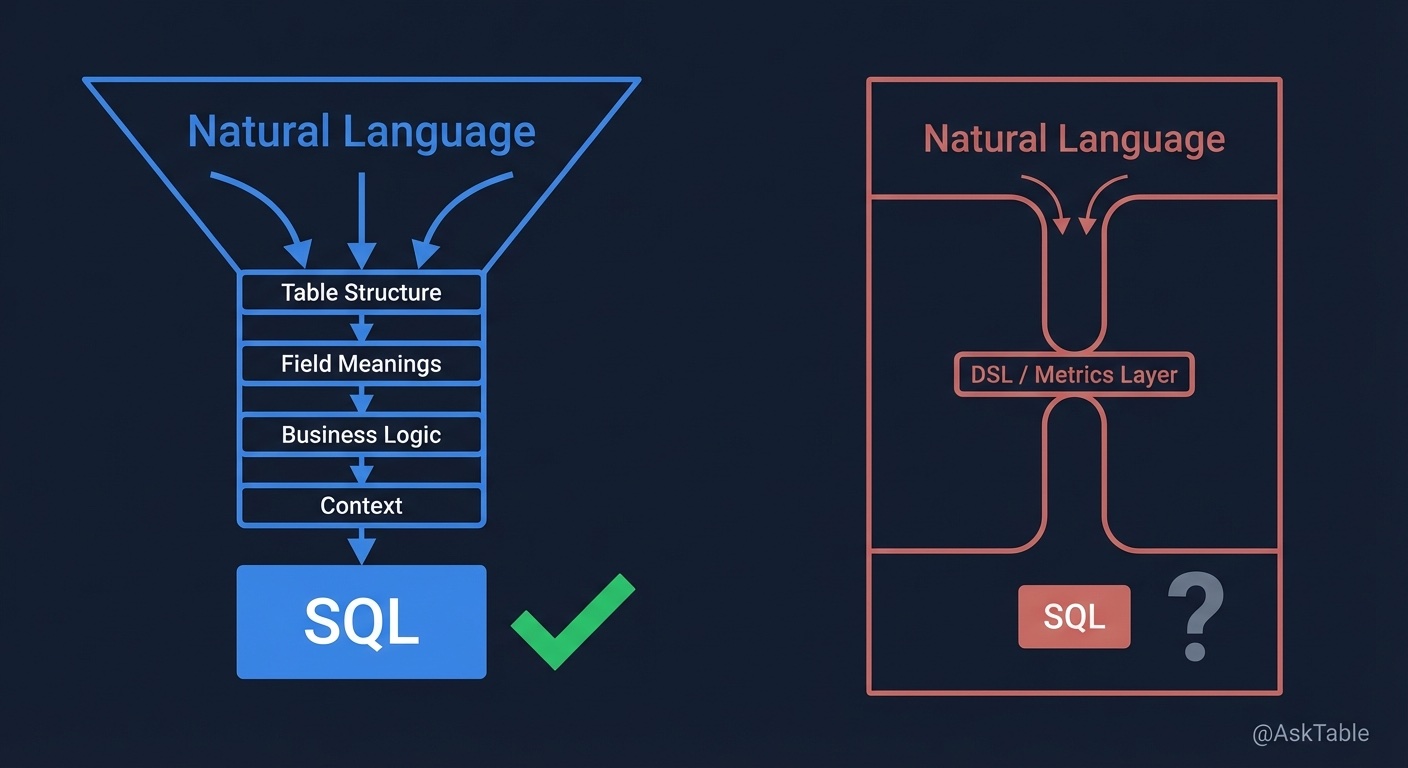
What can the latter approach do? Improve efficiency. Indeed.
And in scenarios with particularly many fixed query patterns, the middle layer approach has irreplaceable value. When query patterns don't diverge, when creativity isn't needed, when it's the same metric criteria being queried day after day - in these cases, DSL's speed advantage becomes apparent, and it's stable, won't cause unexpected issues.
Honestly, this isn't a zero-sum game. Neither approach is absolutely correct. The choice depends on what kind of team you are, what your query patterns are, and whether your business needs those "unexpected" surprises.
But that's about it.
No surprises. No aha moments. No moments that make you think "wow, this is possible." New capabilities and value - there are none. It can only do what you used to do, just slightly faster.
This is the biggest waste. Not computing power, but imagination.
Your own imagination is constrained by the box you set.
Sometimes I think this is exactly like the early days of the Industrial Revolution. Back then, we had internal combustion engines, had automobiles. But many people weren't comfortable, so they attached horse reins and whip holders to cars. They called it a "horseless carriage."
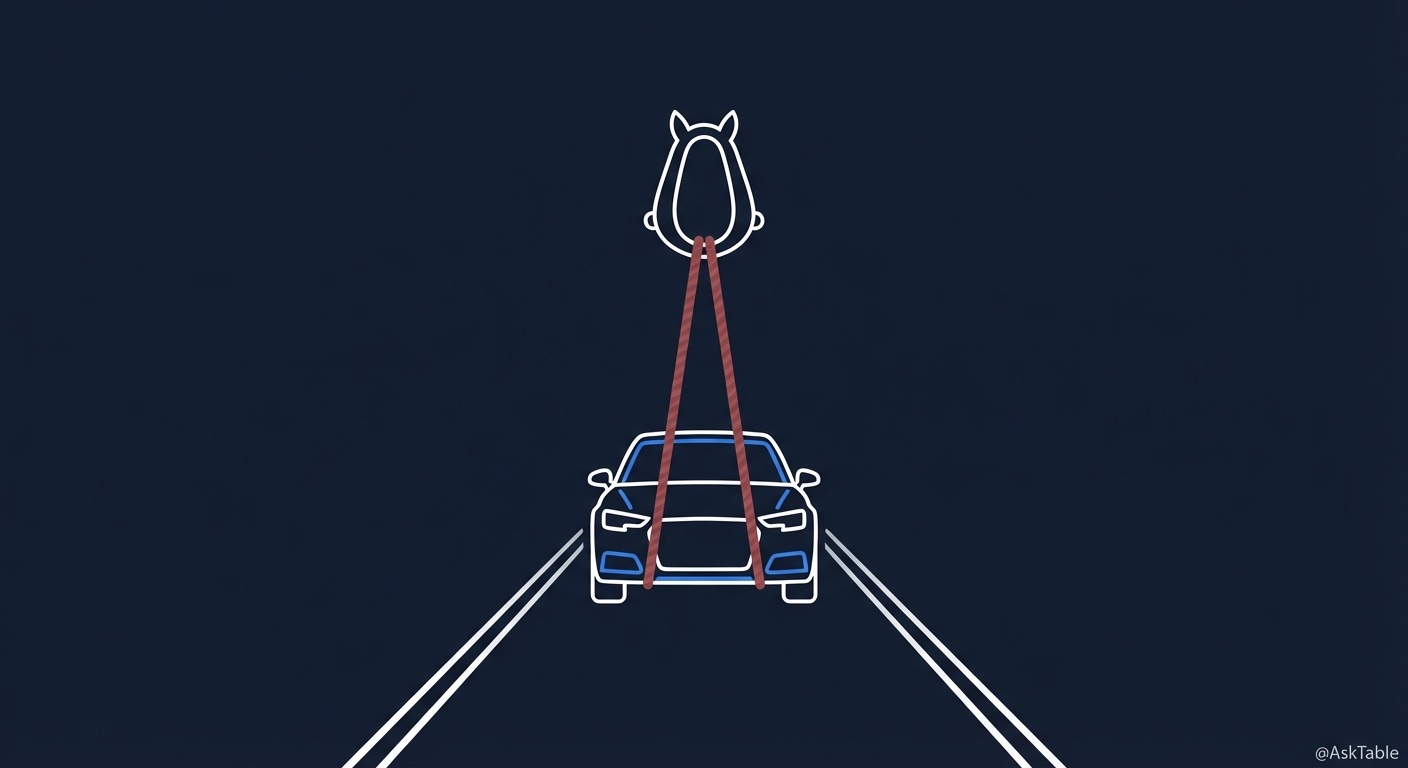
You can understand them. A new technology came, they were afraid of losing control, afraid of problems, so they wrapped it in a familiar framework. But have you thought about it - the ceiling of the automobile was constrained by those reins. Its speed, its flexibility, its possibilities - all limited by that box.
What we're doing now is exactly the same.
We always worry about LLMs losing control. Afraid they'll write wrong SQL, afraid they misunderstood the criteria, afraid of hallucinations. So we add boxes, add semantic layers, add metric management, add validation layers. Every layer comes from good intentions, from caution. But layer by layer, what LLMs can do is reduced to "improving efficiency within the box."
I'm not saying these frameworks have no value at all. In some scenarios, in some fixed scenarios with extremely high accuracy requirements, in some industries with extremely strict compliance - these boxes are necessary. I admit that.
But what if you're not working in those scenarios? What if it's just general business analysis, general operational queries, general data exploration? Do you still need to add three layers of boxes?
I'm still exploring myself. Honestly, when we built AskTable, we fell into this trap too. Later we realized - this isn't a technical problem, it's a trust problem.
Do you dare to give it complete context?
If you do, it will likely give you a surprise. If you don't, it will give you a "just acceptable" answer. Then you say, "see, AI-generated SQL is still inaccurate."
Trust me - it's not that it's inaccurate. It's that you didn't give enough.
So how do you give context?
Take AskTable as an example - we did several things. Preference training and evaluation so the model understands user habits. Skill systems, memory mechanisms, style adaptation. These are all context.
But honestly, it's not enough.
Because complete context goes far beyond this. Enterprise knowledge bases, external industry information, enterprise decisions/actions (Action in ontological concepts) - it's all in there. And this is a long-term effort. Today you give 80%, tomorrow you discover you're still short 20%. There's no shortcut, only continuous refinement.
But the direction is right. Give how much, and the LLM will give back how much.
I've also discussed this with many teams. They don't argue about technical approaches - they just do one thing: get their data context in order. Table structures, field comments, business terminology, calculation criteria - standardize everything. Then throw it to the LLM. The result? Accuracy soars.
No middle layer needed. No DSL needed. No semantic management needed.
What you need is just a complete, clear, accurate data context. Then use the LLM as a truly capable person, not a temporary worker who needs strict management.
That said, why are technical approach debates meaningless? Because they discuss implementation paths, not the problem itself. The world has suffered from data - the suffering is that no one wants to do the dirty, tiring work; the suffering is that data context is always a mess; the suffering is that everyone knows it should be organized but everyone procrastinates.
When you solve the context problem, the technical approach debates dissolve on their own. Because you'll see - LLMs can directly write decent SQL without you first spending three months building a metric system. They can also take the middle layer path, depending on what you need.
It only needs you to trust it and give it what it needs.
A story comes to mind from long ago. During the Apollo moon landing program, the navigation computer had only 72KB of memory. Now even an emoji on your phone is larger. But that computer put humans on the moon. Why? Because they didn't spend energy debating "which programming language is more elegant." They gave the computer all the context, all the preparation they could. Then the computer did something everyone thought was impossible at the time.
It's the same with LLMs. Their capabilities have far exceeded our imagination. The one going beyond the scope isn't them - it's us.
It's us who are still managing a person more capable than any engineer we've seen, with the mindset of managing an intern. It's us who are still limiting a partner that could bring us surprises, with the fear of "can't let it make mistakes."
When we got to the end of this discussion, I think it's actually very simple.
You trust it, give complete context, it gives you results beyond expectations. You don't trust it, add layers of boxes, it gives you an error-free but mediocre answer. Then you think "AI is only so good."
You think AI's ceiling is here.
But AI's ceiling was never the problem. The question is our ceiling.
Our imagination is constrained by ourselves.
We're still debating whether cars should run faster than horses, while others are already building airplanes.
It's a big era, folks.
Alright, since you've made it this far, if you think this was good, feel free to like, share, and subscribe. If you want to receive updates第一时间, you can also follow our WeChat public account (AskTable).
Thanks for reading. See you next time.
sidebar.noProgrammingNeeded
sidebar.startFreeTrial
