
微信

飞书
选择您喜欢的方式加入群聊

扫码添加咨询专家
如果你在企业里做过业务,大概率经历过这样一个场景:
这个场景,在 90% 的中大型企业里每天都在上演。
今天这篇文章,我想深入聊聊这个被所有人吐槽过、但很少有人真正解决的问题:业务部门和技术部门之间围绕"要数据"这件事的无尽拉扯。
以及,为什么 AskTable 用一种简单到几乎"朴素"的方式——技术团队准备好 3-10 张底表,业务人员想怎么查就怎么查——终结了这场拉扯。

让我们还原一个"取数需求"从提出到交付的完整过程:
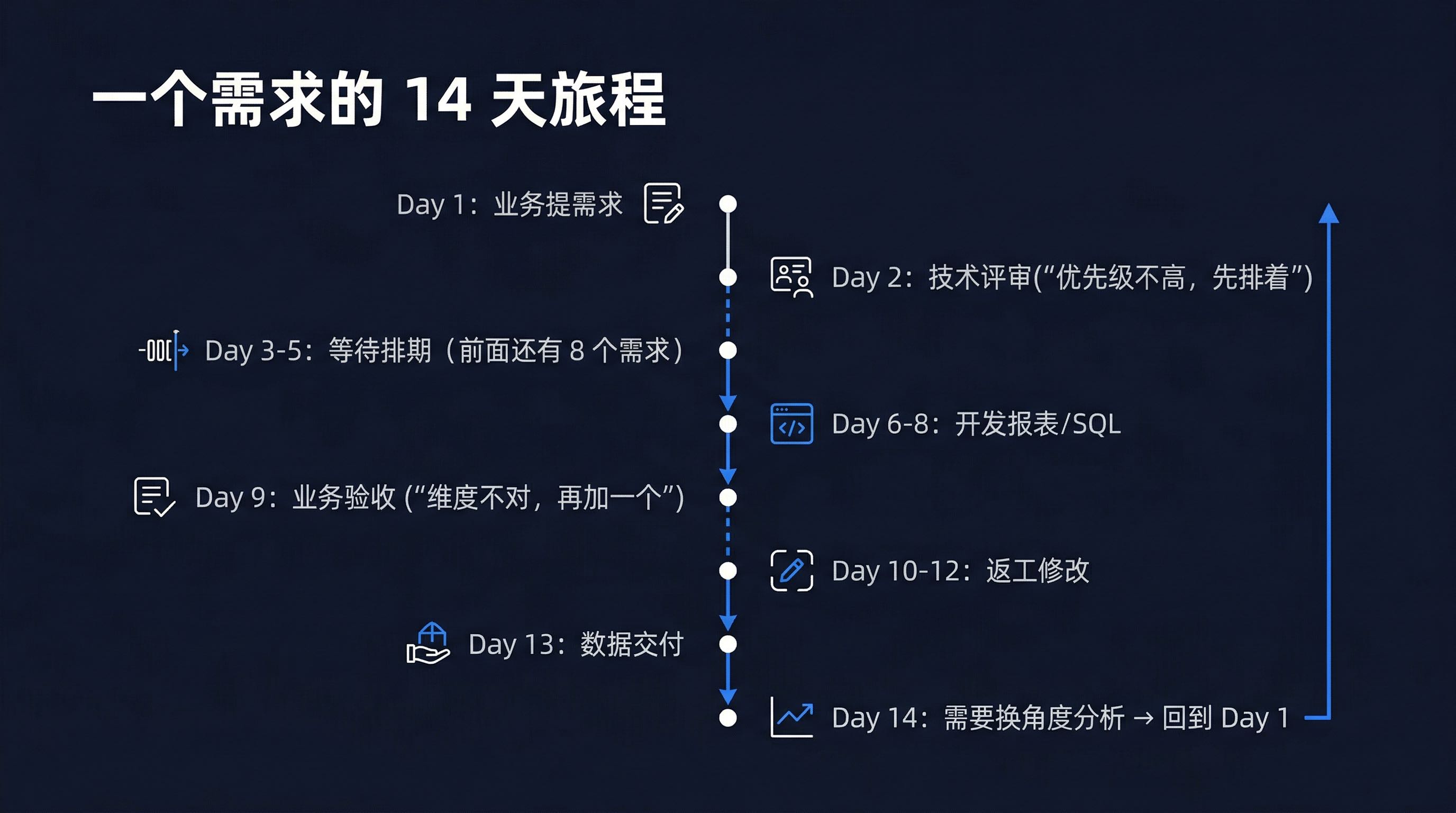
Day 1: 业务提需求
↓
Day 2: 技术评审("这个需求优先级不高,先排着")
↓
Day 3-5: 等待排期("前面还有 8 个需求在做")
↓
Day 6-8: 开发报表/SQL
↓
Day 9: 业务验收("不对,维度少了,再加一个")
↓
Day 10-12: 返工修改
↓
Day 13: 数据交付
↓
Day 14: 业务发现还需要换个角度分析 → 重新从 Day 1 开始
从提出问题到拿到数据,两周是常态。 如果遇上需求高峰期、人员变动、系统升级,一个月也不稀奇。
假设一个中型企业(500-1000 人),每月有 200 个取数需求:
| 环节 | 时间 | 人力 | 月度成本(按 800元/天) |
|---|---|---|---|
| 业务提需求、沟通口径 | 0.5天/需求 × 200 | 业务人员 | 80,000 元 |
| 技术评估、排期、等待 | 5天/需求 × 200 | 时间成本 | (决策延迟的隐性成本) |
| 开发报表/SQL | 1天/需求 × 200 | 数据工程师 | 160,000 元 |
| 返工修改(30%概率) | 2天/需求 × 60 | 数据工程师 | 96,000 元 |
| 合计 | 336,000 元/月 |
这还只是显性的人力成本。更可怕的是决策延迟的隐性成本——
当你等两周才拿到数据时,市场窗口可能已经关闭了。
在实际的企业运作中,还有一个更隐蔽但影响更大的问题:
数据分析的资源和能力,往往集中在少数人手中——通常是部门负责人或高管。
原因很简单:
结果就是:一线业务人员越是急需数据做决策,越拿不到数据。 因为他们排队排不过领导的"战略分析需求"。
这就造成了一个悖论:最需要数据做一线决策的人,离数据最远。
当业务抱怨"技术太慢"、技术抱怨"业务需求变来变去"时,双方的视角都是真实的:
业务部门的委屈:
技术部门的无奈:
双方都没错。错的是中间的传递架构。
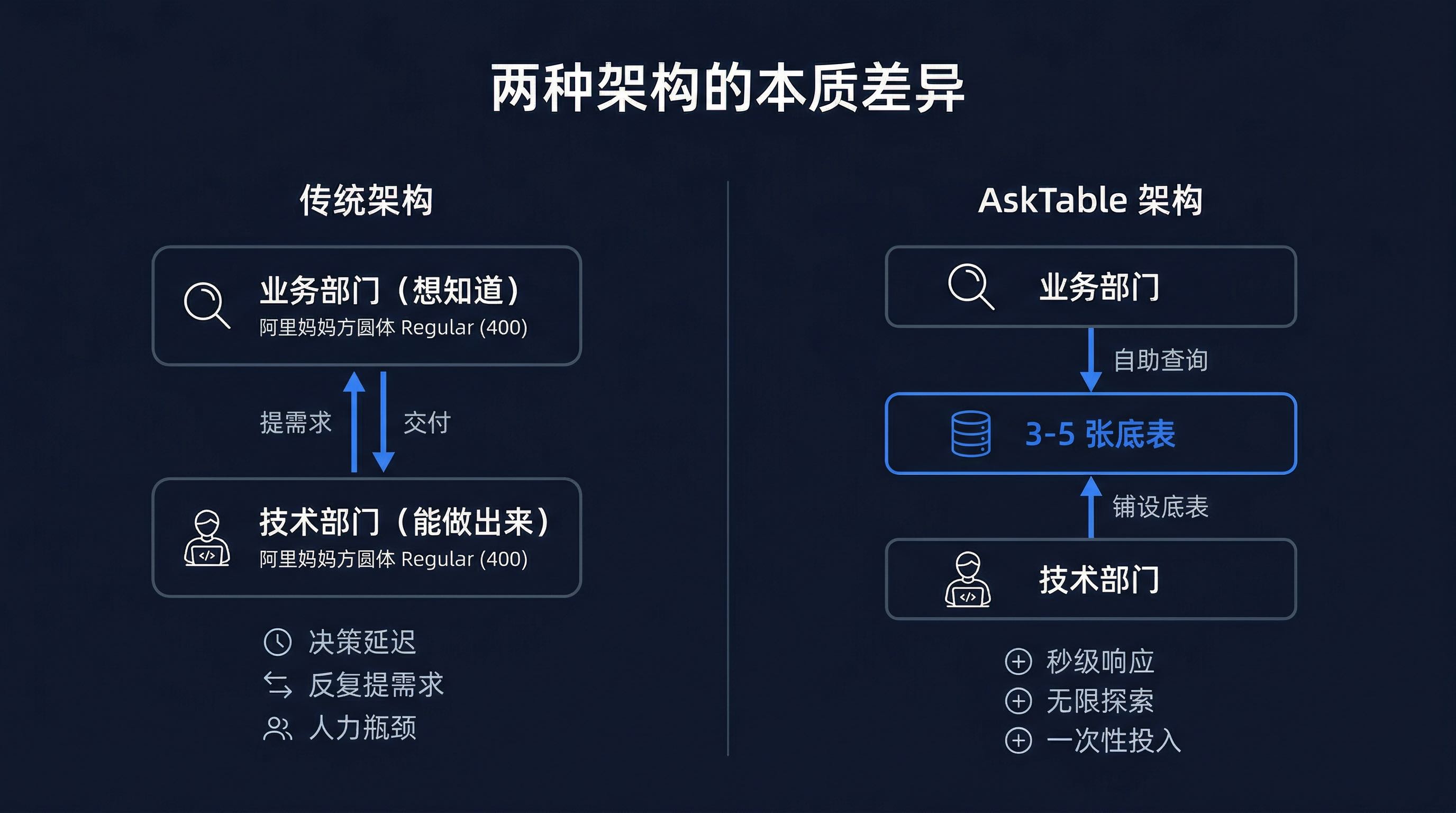
这个架构有三个致命问题:
第一,需求传递链太长。
业务人员不懂 SQL,技术人员不懂业务。每次需求传递都是一次"翻译",翻译就会丢失信息。所以返工率高达 30%。
第二,供给能力是线性的。
一个数据工程师一天能做 1-2 个需求。200 个需求就需要 100-200 人天。加人意味着成本线性增长,而且新人上手还需要时间。
第三,探索性分析被彻底扼杀。
业务人员如果有"我就想看看"的好奇心,在传统架构下是不被允许的——因为"看看"也是需求,也要排队。久而久之,业务人员不再主动探索数据,只在出大问题的时候才想起要数。
这不是数据分析,这是数据救济。

AskTable 对这个问题的解决思路,简单到有些"反直觉":
技术团队不需要帮业务做 200 张报表。技术团队只需要帮业务准备好 3-10 张底表。剩下的,让业务自己查。
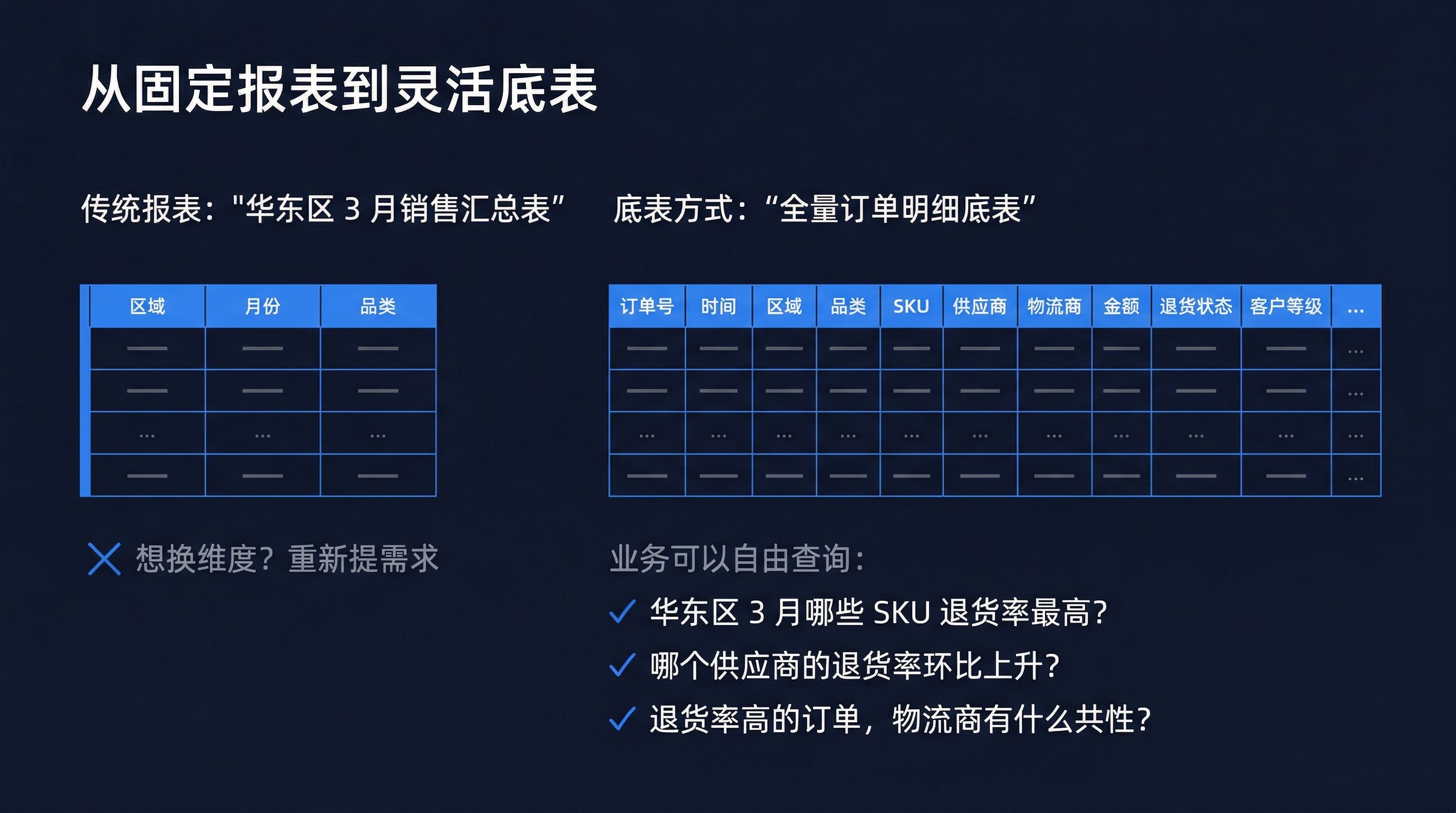
底表不是报表,不是仪表盘,不是固定的统计结果。
底表是结构化的、干净的、包含足够维度的数据基础层。它类似于数据仓库中的"宽表"或"数据集市",但粒度更细、维度更全。
举个例子:
❌ 报表(传统方式):
"华东区 3 月销售汇总表"
—— 固定维度:区域、月份、品类
—— 如果想看"按供应商拆分"?重新提需求。
✓ 底表(AskTable 方式):
"全量订单明细底表"
—— 包含字段:订单号、时间、区域、品类、SKU、
供应商、物流商、金额、退货状态、客户等级……
—— 业务人员想怎么查就怎么查:
"华东区 3 月哪些 SKU 退货率最高?"
"哪个供应商的退货率环比上升了?"
"退货率高的订单,物流商有什么共性?"
技术团队的工作从"无限度做报表"转变为"建设好底表":
技术团队职责:
│
├── 1. 梳理业务需要的核心数据实体
│ └── 通常 3-5 张,一般不超过 10 张
│
├── 2. 确保底表数据质量
│ └── 字段完整、口径统一、更新及时
│
├── 3. 在 AskTable 中配置数据源
│ └── 连接数据库,同步元数据,配置行级权限
│
└── 4. 教会业务人员用自然语言提问
└── 通常 30 分钟培训即可上手
技术团队的一次性投入,换来的是业务部门的无限次自助查询。
业务人员的工作从"提需求等数据"转变为"自己查自己分析":
业务人员日常:
│
├── 想查什么,直接问
│ └── "上个月华东区退货率最高的 Top 10 SKU 是哪些?"
│
├── 想深入分析,继续追问
│ └── "这些 SKU 的供应商有什么共性?"
│ └── "按物流商维度拆一下看看。"
│
├── 想做对比分析
│ └── "对比一下这两个供应商的退货率趋势。"
│
└── 想生成报告
└── "把上面的分析生成一份报告,我下午开会要用。"
全程不需要写 SQL,不需要等技术排期,不需要反复沟通口径。
传统架构:
┌──────────┐ 提需求 ┌──────────┐
│ 业务 │ ─────────────→ │ 技术 │
│ (等) │ │ (做) │
└──────────┘ └──────────┘
↓
排期 → 开发 → 交付
周期:1-2周
AskTable 架构:
┌──────────┐ ┌──────────┐
│ 业务 │ ←── 3-5 张底表 ─────→ │ 技术 │
│ (自查) │ │ (铺底) │
│ │ └──────────┘
│ 想怎么查就怎么查 一次性投入
│ 秒级响应
│ 无限探索
└──────────┘
"让业务自己查数据"这个想法,其实并不新鲜。但为什么过去十几年都没做成,现在 AskTable 能做成?
尝试一:BI 自助分析工具
各类 BI 工具(帆软、QuickBI)号称"自助分析",但实际使用门槛依然很高:
尝试二:固定报表 + 仪表盘
把常用的报表做出来,放到仪表盘上。问题是:
尝试三:让业务学 SQL
有些企业尝试培训业务人员写 SQL。结果是:
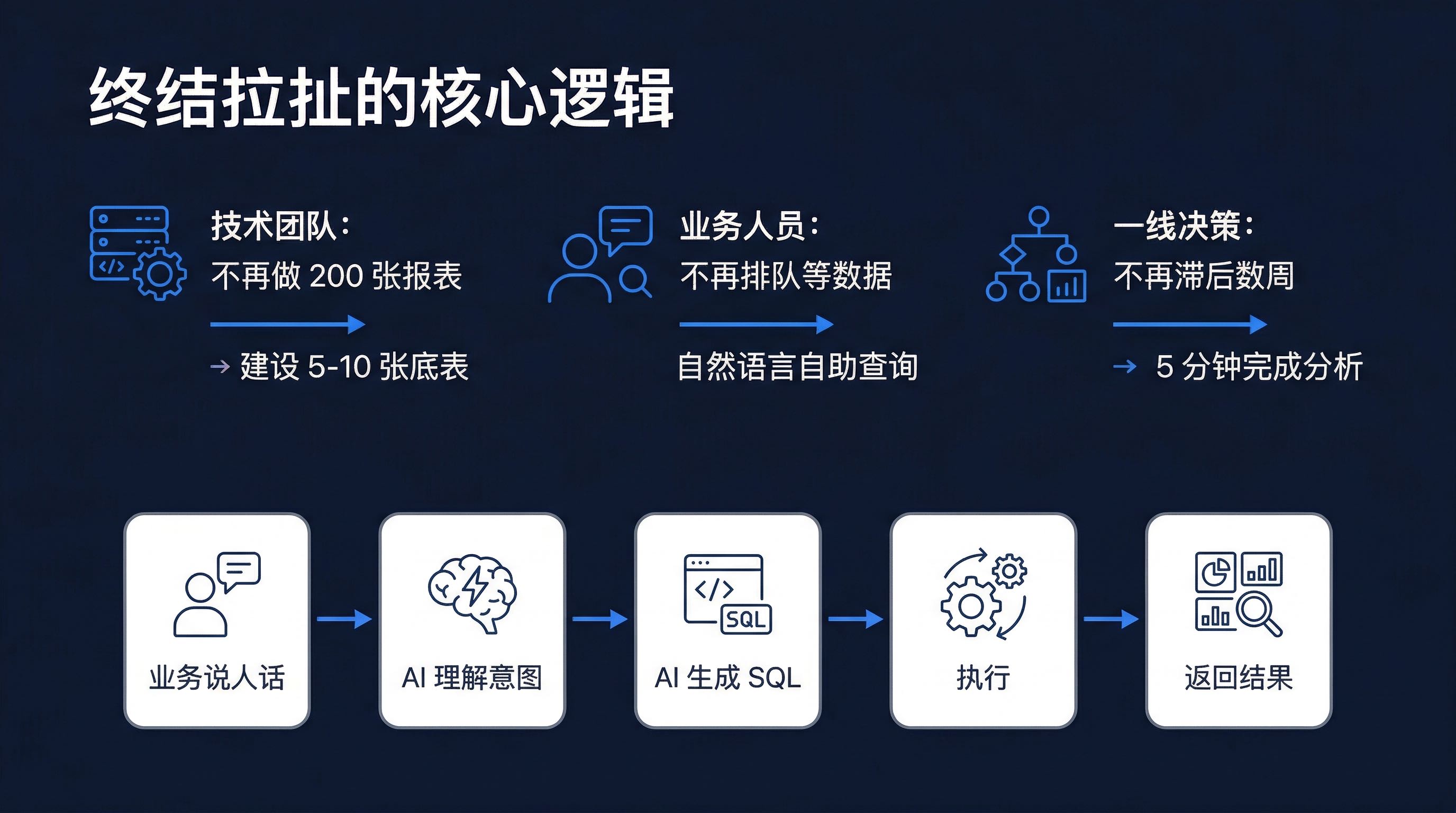
AskTable 的核心突破是:用 AI 做翻译层。
业务说人话 → AI 理解意图 → AI 生成 SQL/Python → 执行 → 返回结果
这背后依赖几个关键能力:
1. Text-to-SQL 的成熟
过去两年的大模型进步,让自然语言转 SQL 的准确率从不到 60% 提升到了 85% 以上。AskTable 内置的 SQL 生成能力,配合 20+ 种数据库的支持,覆盖了绝大多数企业的数据场景。
2. 元数据智能标注
AskTable 连接数据源后,会自动扫描表结构、字段信息,并基于字段名和数据样本生成中文业务标签。业务人员不需要知道底层表叫 t_order_detail_v3,只需要说"订单数据"就行。
3. 权限与安全兜底
4. 异常检测与归因分析
AskTable 不只是执行查询,还能主动发现问题:
这是传统 BI 工具做不到的——传统工具只能回答你问的问题,AskTable 还会告诉你你没注意到的问题。
关于 AskTable 的 AI Agent 架构设计和内置技能系统,我们有专门的文章深入解析。

Before:传统模式(两周)
Day 1 - 业务发现异常,提需求:
"帮我拉一下华东区近 30 天各 SKU 的退货明细,
按供应商和物流商拆分。"
Day 2-3 - 技术评审排期:
"这个需求优先级中等,预计下周做。"
Day 7-8 - 开发完成:
"报表做好了,你看看。"
Day 9 - 业务验收:
"数据拿到了。但我还想按批次号追溯一下,
看看是不是某一批次的质量问题。"
Day 10 - 技术回复:
"这个需要加字段,重新排期,预计下下周。"
Day 17 - 第二批数据交付:
"数据来了。"
Day 18 - 业务终于开始分析,
但异常已经持续了近一个月。
After:AskTable 模式(5 分钟)
第 1 分钟:
业务:"上个月华东区各品类的退货率是多少?"
AskTable:返回结果,自动标注异常值。
"我注意到电子配件品类的退货率为 12.8%,
远高于其他品类的 3-5%。"
第 2 分钟:
业务:"电子配件里哪些 SKU 退货率最高?"
AskTable:返回 Top 10 SKU 列表。
第 3 分钟:
业务:"这些 SKU 的供应商有什么共性?"
AskTable:自动归因分析。
"这 10 个 SKU 中有 7 个来自同一家供应商 C,
且都在最近 30 天内更换了物流商。"
第 4 分钟:
业务:"按物流商维度对比一下退货率。"
AskTable:生成对比图表。
"物流商 D 的退货率是 18.6%,
其他物流商平均 4.2%。"
第 5 分钟:
业务:"生成一份分析报告,我要马上发给采购团队。"
AskTable:自动生成结构化报告。
第 5 分钟 - 决策已经做出:
"暂停与物流商 D 的合作,排查供应商 C 的最近批次。"
| 维度 | 传统模式 | AskTable 模式 |
|---|---|---|
| 首次响应时间 | 1-2 周 | 10 秒 |
| 完整分析周期 | 2-4 周 | 5 分钟 |
| 需要技术介入 | 每次 | 仅铺底表一次 |
| 探索性分析 | 不支持(成本太高) | 随时进行 |
| 返工率 | 30%+ | 接近 0(业务自查自验) |
| 月度数据需求处理量 | 50-100 个(人力瓶颈) | 无上限 |
| 一线决策延迟 | 2-4 周 | 5 分钟 |
| 资源被领导占用 | 严重 | 缓解(各查各的) |
不要一上来就全公司推广。选一个:
典型的切入点:运营监控、销售分析、供应链异常排查。
和技术团队沟通,让他们梳理出这个场景需要的核心数据:
底表设计的原则:宁可多给维度,不要少给。 因为底表一旦做好,业务可以自己裁剪维度,但如果少了一个关键字段,又得找技术加。
通常 1-2 天可以完成。
30 分钟的业务培训,教会业务人员:
当第一个场景跑通后,你会看到立竿见影的效果:
然后,把同样的模式复制到其他业务场景。
回顾这个解决方案,最值得我们深思的不是技术层面的突破,而是权力结构的重构。

在传统模式下,业务部门向技术部门"要"数据,本质上是一种数据乞讨:
在 AskTable 模式下,业务部门直接访问数据:
这不是工具升级,而是数据民主化的实现。
在传统模式下,数据分析资源被领导占用是必然的——因为资源稀缺,自然会向权力集中。
当分析变得足够简单和廉价,每个人都可以是自己的数据分析师。一线业务人员不再需要等待,不再需要求人,不再因为拿不到数据而做出盲目决策。
传统模式下,技术部门被动响应业务需求——业务不问,技术不说。
AskTable 的 AI Agent 会主动发现问题并提醒业务人员:
"我注意到本周退货率比上周上升了 8 个百分点,主要集中在 A 供应商的 B 品类。需要深入分析吗?"
这种从"你问我答"到"我主动告诉你"的转变,才是 AI 数据分析最大的价值。
企业里业务和技术之间围绕"要数据"的拉扯,本质上是一个架构问题。
传统架构的核心矛盾是:业务的数据需求是无限的、变化的、探索性的,而技术的供给能力是有限的、固定的、被动响应的。
AskTable 用一种极简的方式解开了这个结:
这条路的核心逻辑和我们在 企业 AI 落地的第三条路 中讨论的"能力编排"思路是一致的:不把精力花在造轮子上,而是用成熟的能力组合解决业务问题。
当你的竞争对手还在为取数需求排队两周时,你的业务团队已经用 5 分钟完成了数据查询、深入分析和决策制定。
这大概就是数据分析的未来——不是更多报表,而是更少等待。
核心观点:业务要数据不应该像讨饭,技术做报表不应该像春运。问题的解法不是加人,而是换架构——技术铺好底表,业务自助查询,让每个人都能在自己的决策半径内拿到数据。
